Recurrent neural networks


Within the field of deep learning or deep learning, there are many different neural network architectures and morphologies. Each one specializes in a specific type of task.
For example, convolutional neural networks have the characteristic that they accept information encoded in 4-dimensional tensors, such as images, so when we have to work with image data we will use them.
To work with text, and in general, with sequence data, the most optimal neural networks are those known as recurrent neural networks.
In today's article we will give an introduction to recurrent networks, we will explain how they work, the types that exist and what applications they currently have.
What are recurrent neural networks?
Recurrent neural networks (RNN) are a type of artificial neural network specialized in processing sequential data or time series whose architecture allows the network to obtain artificial memory.
This type of artificial network helps make predictions of what will happen in the future based on historical data. For example, we can use recurrent neural networks to predict the sales volume of a certain product. This helps predict the stock needed and save money.
They are also very useful for analyzing text and generating new ones from existing ones. There is a movie that was filmed a few years ago whose script was generated by artificial intelligence that used this type of neural networks.
The architecture of this type of model allows artificial intelligence to remember and forget information. In this way, the AI is capable of remembering the text processed dozens of sentences ago and associating concepts with the new sentences it analyzes.
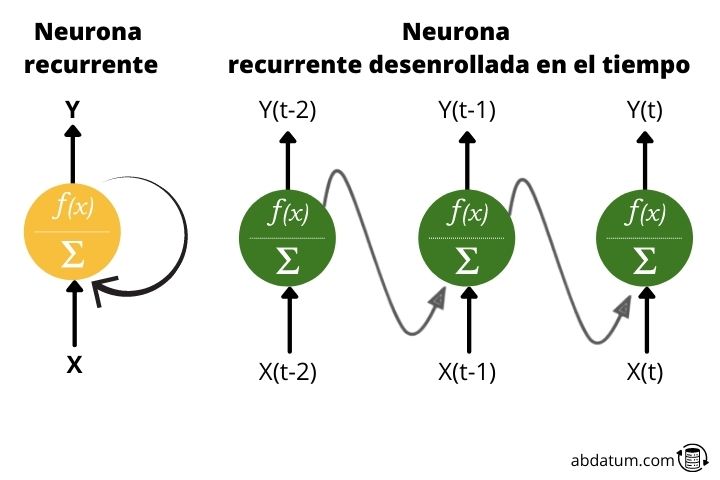
The recurrent neuron
We have seen that these types of networks have memory. How do they get it?
Let's start with the basics. What is a recurrent neuron?
Typically, when you talk about neural networks, activation functions only move in one direction: forward.
A recurrent neuron transmits information forward but also has the characteristic of sending information backward. Therefore, at each step, the recurrent neuron receives data from the previous neurons, but also receives information from itself in the previous step.
For practical purposes, this type of cyclic connections are not efficient, so a deployment is established to generate a cycle-free architecture, much more suitable for applying mathematical optimization tools.
Types of recurrent neural networks
There are different variations of recurrent neural networks depending on the format of the input and output data that we want to obtain.
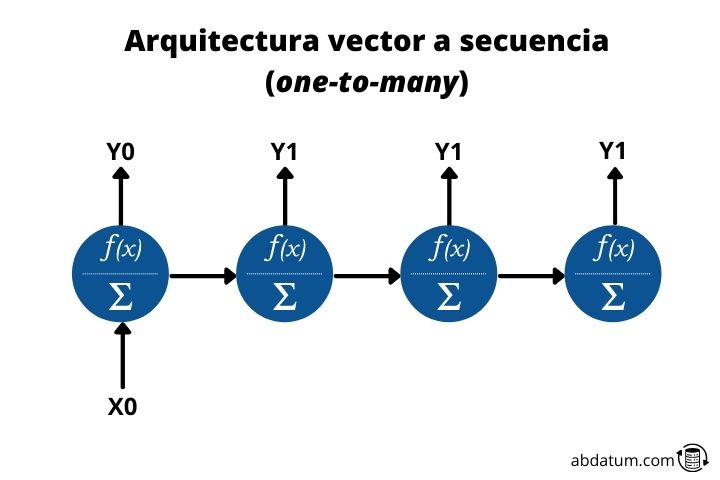
Vector to sequence or one-to-many
This type of architecture allows the input of one data and the output of many data in sequence. That's where the English name one-to-many comes from.
An example would be a model that could describe it to us based on an image. Therefore, a single piece of data would enter the network, in this case the image, and we would obtain a sequence of data, the text, which would be the description of the image.
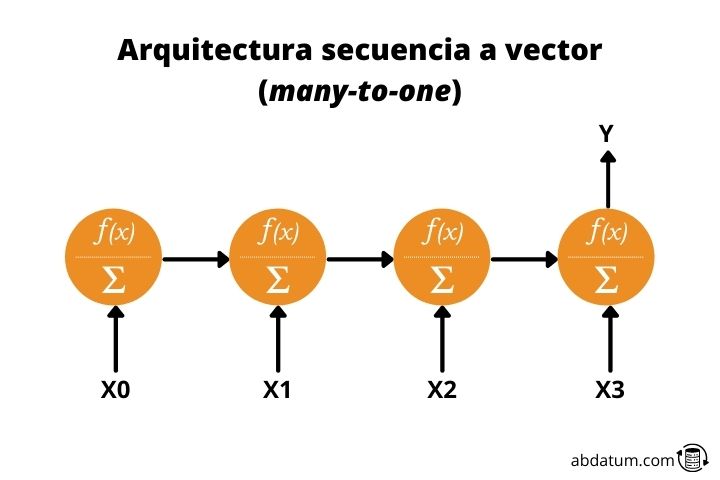
Sequence to vector or many-to-one
This type of architecture is just the opposite of the previous one. We give a sequence as input value and obtain a unique data.
For example, a model that received a description of an image and created said image would be a many-to-one recurrent neural network.
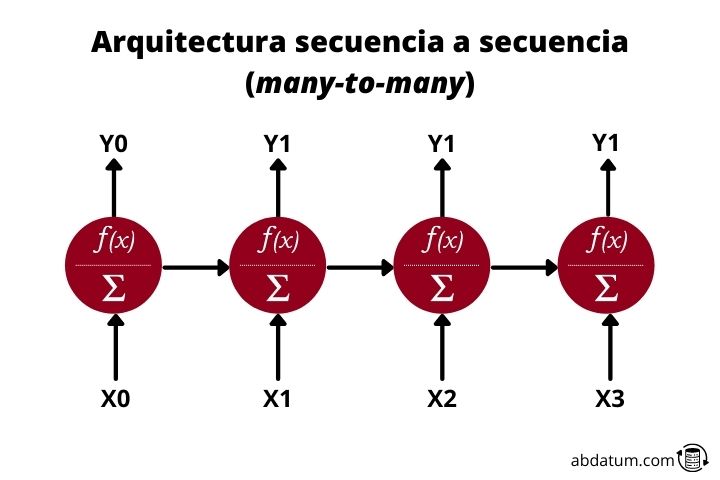
Sequence to sequence or many-to-many
Finally we have many-to-many recurrent networks. This architecture receives sequential input data and creates sequential output data. A very clear example is intelligent translators.
They receive a text, for example, in Spanish and generate a new text, for example, in English. They are also used to generate text summaries or to convert text to audio or audio to text.
Memory cells or memory cells
As we have seen in previous schemes, information flows from one neuron to another over a longer period of time. Therefore, the input data is a function of the input data at previous times.
All new information is added to the data flow, a fact that allows this type of networks to have memory. In short, RNNs have information from previous times at each timestep, that is, they can remember what was seen previously in the sequence.
This allows, for example, that when a text is introduced into the recurrent neural network, it can relate distant concepts in the sequence.
Short-term memory problem ( short-term memory )
The memory of this type of networks is limited, so the effective transmission of information between sequences that are very far apart is difficult.
This is due to what is known as gradient fading or gradient vanishing .
This problem happens when, during the training of the recurrent neural network, the weights become smaller and smaller, causing the gradient to also decrease and the weights of the network are barely updated, losing the learning capacity of the model.
LSTM and GRU recurrent neural networks
To solve the problem of short-term memory, what are known as doors or gates in English. These gates are basically mathematical operations such as addition or multiplication that act as mechanisms to store relevant information and eliminate information that is not relevant to learning.
The two most important types of networks with these mechanisms that allow longer-term memory are LSTMs ( Long-Short Term Memory ) and the GRU ( Gated Recurrent Units ).
LSTM ( Long-Short Term Memory )
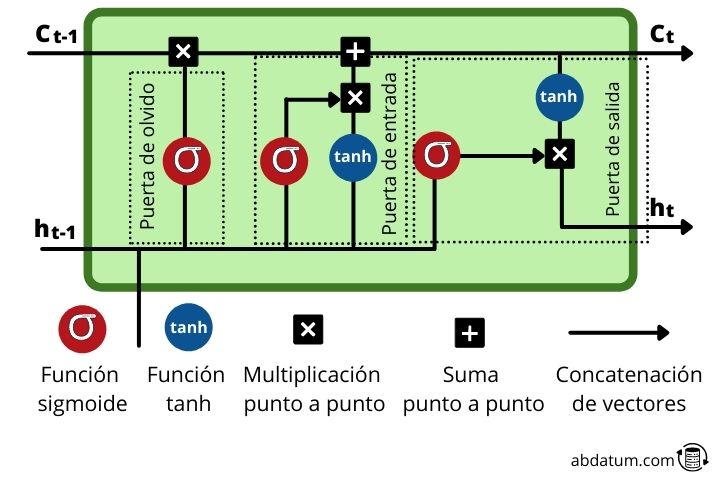
LSTMs are a type of recurrent neural networks where each memory cell or memory cell It has a group of very specific operations that allow controlling the flow of information. These operations, called gates, allow us to decide whether certain information is remembered or forgotten.
Within the memory cell new information is added to that which comes from previous sequences, that is, from previous time steps. As we will see, new relevant information is added to the flow thanks to an addition operation.
Let's look at these mechanisms in more detail:
- Gate of oblivion or forget gate : This gate decides what information remains and what is forgotten. This is achieved with the sigmoid function which has a domain from 0 to 1. The closer to 0, the less important it is and the closer to 1, the more important it is.
- entrance door or input gate : The role of this gate is to update the hidden state of the cell. For this task, the new input it is added to the hidden state of a previous time. The amount of information that is retained is controlled with the sigmoid function, transforming the values between 0 and 1. Zero means that it is unimportant and can therefore be eliminated. Unity means that it is important and that knowledge must remain.
- exit door or output gate : This gate is responsible for deciding what the hidden state of the cell will be in the timestep following. To do this, it uses the sigmoid and tanh functions.
- tanh function : this function that we see repeatedly within the memory cells has the function of compressing the values between 1 and -1 to prevent these values from increasing too much or decreasing too much and thus avoid gradient problems during training that would make it difficult to learn the grid.
GRU ( Gated Recurrent Units )
GRUs are recurrent neurons with a somewhat different structure than LSTMs. They are newer and eliminate some of the operations of LSTMs.
GRUs do not use the cell state ( cell state ), they only use the hidden state for the transfer of information. Additionally, they have 2 doors or gates differentiated: the update door or update gate and the reset door or reset gate .
- Upgrade Door : This type of GRU gate is similar to the function of the forget and entry gates of LSTMs. The objective of which is to keep information relevant and eliminate data that is not important.
- reset door : This gate controls the amount of information that is forgotten during network learning.
As we see, GRUs have fewer operations and are therefore faster to train than LSTMs.
For practical purposes both network morphologies work well. Which one is better will depend on the type of problem and, therefore, it is best to try both architectures, both the GRUs and the LSTMs, to determine which one obtains better results.
Applications of the recurrent neural networks
There are multiple examples of uses and applications of this type of neural networks. Below we show you some so that you can get an idea of the power that recurrent neural networks have.
Smart translators
Translators trained with artificial intelligence make use of this type of artificial neural networks to generate translated text.
They can also be used for real-time translations where the input data is the speaker's voice and the output data is artificial speech with the translated text.
This type of neural network morphology has greatly improved the quality of translated texts, since previously, memory-based functions were used.
Smart chatbots
RNNs are also used to generate automated bots that are capable of answering questions that potential customers may have. On many web pages we see a chat with which we can interact and talk to resolve questions about the product.
Many of these chats work with artificial intelligence trained specifically for this type of function. These models are normally LSTMs or GRUs.
Sales prediction
Apart from text, we can also use other types of sequential information such as time series. Many businesses use models of machine learning to carry out sales predictions and thus save on stock.
Therefore, RNNs are also used to make price predictions based on historical data of past sales.
Virtual assistants
The last example is virtual assistants. If we have Apple devices we will know that we can ask Siri for actions to execute. The same if we have Alexa, from Amazon.
These assistants are able to interpret commands in a variety of different languages and carry out the actions requested.
In order to understand the information that is transmitted, they use RNN neural networks.