Relational database, discover the relational model and some examples

We live in the era where managing data is essential for most companies and businesses in the world.
The largest technology companies in the world such as Netflix, Amazon, Google or Facebook make use of this information to give users what they want to see.
Today we will talk about
To do this, they need to store millions and millions of data in an orderly manner so that when required they can be extracted quickly and efficiently.
But... How and where is all this enormous amount of information stored?
Well, yes, you got it right. All this information is stored in a network of computers connected to each other using what we know as databases (BBDD) .
There are different types of databases, but the most used and the one that has been with us the longest is called relational database .
In this article you will learn what they consist of and how they work. In addition, we will give you some tips on how to start managing them.
What are relational databases?
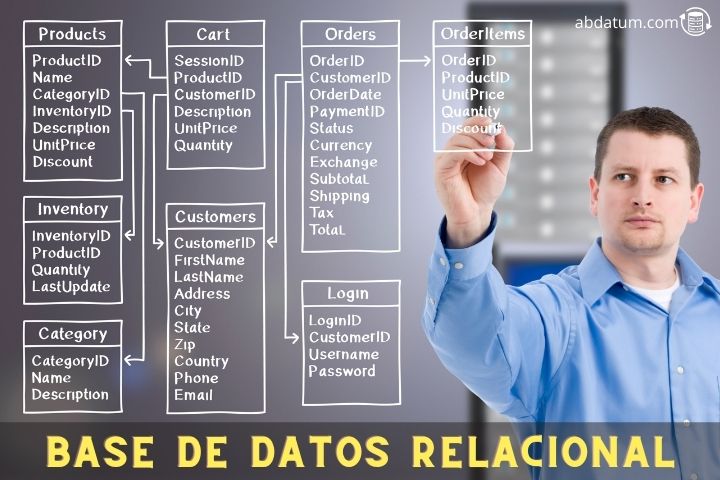
A relational database is a type of database that uses the relational model to represent and create unions between different data so that they can be queried and updated using the SQL language ( Structured Query Language ).
The information is stored in tables where each one has several rows. Each of them has a unique label called a primary key.
At the same time, the table also contains columns called attributes. Each row or record in the table has associated attribute values. Let's take an easy example:
Imagine that we want to register the users of our website. Each user has a first name, a last name, an email and an address.
These characteristics of each of the users define the different columns of the table. Therefore, each user is a different row, that is, a record in the table.
We have mentioned before that each of the records must have a unique and exclusive field. In this way we can differentiate each user without any problem.
In this case it would be the email since two users can have the same first name, even the same last name and they can live on the same street, but they can never have the same email.
Therefore, the user's email would be the primary key and with this we could quickly identify our user.
In the following image we can see a diagram of what our user table would look like within a relational database.
Characteristics of relational databases
This type of database has different characteristics that make it a powerful data warehouse.
One of the main characteristics is to avoid duplication. Having duplicate elements can lead to a misinterpretation of the data.
To avoid this problem, each record is uniquely identified by a primary key. Additionally, tables must also have a unique name.
Another important point is data integrity. These types of models maintain great integrity thanks to the correctness and completeness of the information, preventing the data from being corrupted and new invalid entries being added to the database.
Another peculiarity is the relationships that can be established between different tables. These relationships allow you to join and extract data from different tables as if it were one.
These relationships are carried out using what are known as primary keys and foreign keys. Later we will see what these types of operations consist of.
Entity relationship model
A relational database can be very complex and have many relationships between a wide variety of tables. Therefore, it is important, before starting, to design what structure and architecture it will have.
To represent the structure we can use what is known as the entity-relationship model. This type of representation has some elements that allow us to precisely define all the elements of our relational database. Let's see them:
Entity
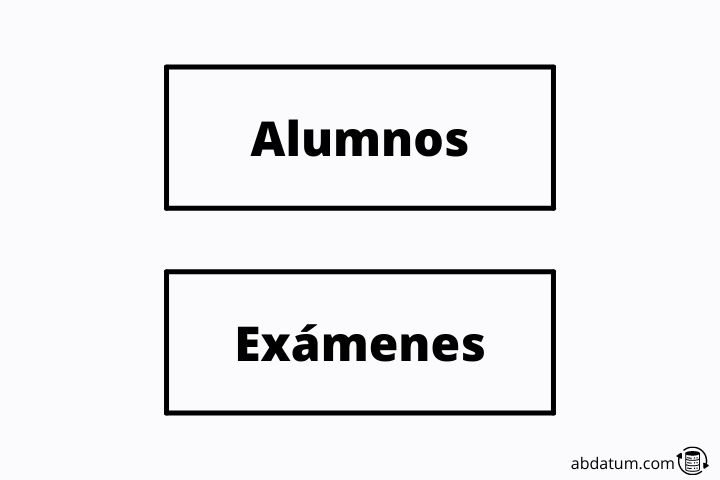
Entities are a representation of objects where each one has specific characteristics. The identities are the tables that we generate in the database. To give an example, imagine an institute where we have many students.
An entity would be “students” which stores the information of each of them. Another entity could be “exams” where the information about the exams that have been taken during the school year is saved.
Another identity could be homework containing information about the different jobs that the students have had to do at home.
These identities are represented as rectangles in the scheme or diagram that we generate to determine the structure of the DB.
Attributes
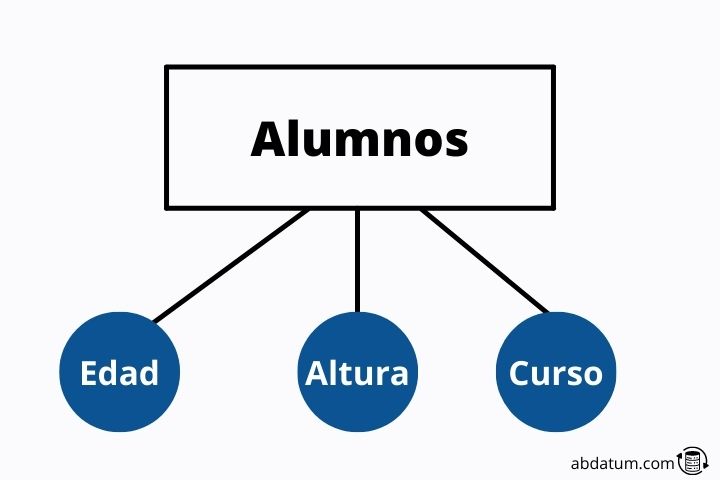
The attributes (columns) are the characteristics that define each element of the identity. For example, student attributes could be: age, height, grade, number of exams passed or number of exams failed.
Each of the attributes provides us with information about each student that contains the identity.
Attributes are represented in the diagram as circles hanging from identities (rectangle symbols).
Relations
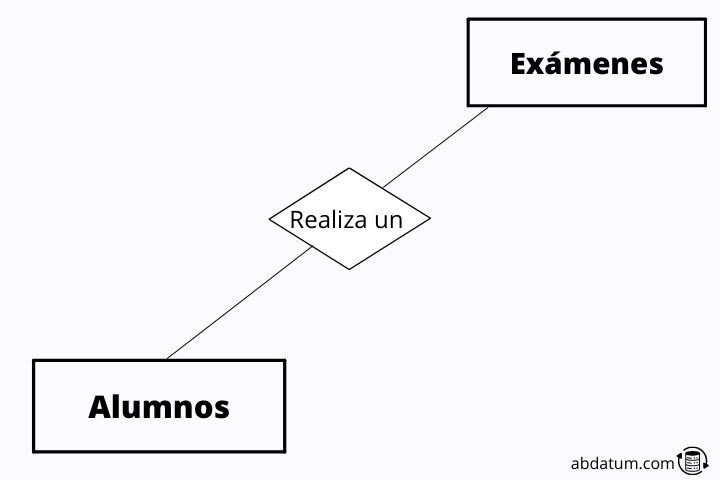
Relationships represent the dependencies that exist between different tables or identities. For example, each student takes different exams during the year, therefore, each student in the table or identity “students” will be related to one or more exams in the table or identity “exams”.
By establishing this relationship we can see the grades that a student has obtained in the different tests carried out during the school year.
These relationships are represented in the entity-relationship model diagram as rhombuses that are joined to the identities by lines.
Keys
- primary key : is a key that identifies a table entry as unique. For example, in our school database it would be a unique identification number for each student in the school.
- foreign key : This field would be, for example, the student identifier in the exam table. In this table the student identification will not be unique since a student takes more than one exam. Therefore, the foreign key must not be unique, but must be related to the unique primary key of the table it relates to, in this case, the students table.
Relational Database Examples
More than examples of databases, we should talk about examples of relational database managers.
A database management system is software whose function is to store, manipulate and extract all types of information from the database.
Some widely known managers in the technological world are the following:
1.MySQL
MySQL is the most popular open source data management system on the planet.
Some of the advantages of MySQL are that it is free, it is a very fast database that allows you to query data very quickly and accurately, it is compatible with most operating systems and it has an encryption and security environment.
Without a doubt, MySQL is a perfect option to implement in web tools or applications.
2. MariaDB
This manager is very similar to the previous one since it was implemented by one of the MySQL developers. These two are very similar in functionality.
However, MariaDB adds some improvements, such as the ability to perform complex queries that can be cached on the computer to improve speed when the query is performed again.
MariaDB allows the use of more complex structures such as hierarchies of graphs . However, in most situations, both managers are valid.
3. PostgreSQL
PostgreSQL, usually called Postgres, is an open source, object-oriented data manager that works with the relational model. Its SQL language is a little different from previous managers.
Complies with the ACID model, providing stored data with Atomicity, Consistency, Integrity and Durability. This prevents stored information from being corrupted.
Advantages and disadvantages of relational databases
some advantages of using relational databases are the following:
- Maturity : This type of database has been with us for a long time, which is why it has a large community and a lot of documentation about it.
- SQL language : All relational databases work with a manager that allows information to be extracted using what is known as SQL ( Structured Query Language ). This allows for unification and for a database to be used with different managers.
- Simplicity : One of its strong points is its simplicity of use. SQL is a language that is very similar to human natural language, so with little time you can learn to use this type of managers.
Difference between non-relational database and relational database
The relational databases They are a collection of objects organized in tables with rows and columns. A programming language known as SQL (Structured Query Language) is used to query, add and modify information in the database.
This type of database uses the relational model and establishes different relationships between existing tables throughout the database.
The non-relational or NOSQL databases They do not establish relationships and do not use tables to store information. They have a flexible structure that allows you to save all types of data: graphs, documents, key-value pairs, etc.
NOSQL databases are optimized to store large amounts of unstructured information. One of its advantages over relational ones is its great scalability.