What is a decision tree


Decision trees are a statistical mathematical algorithm used in the world of data science and machine learning to make predictions. It is an autonomous supervised learning method that can be used for both classification and regression problems.
If you want to learn more about these methods, stay and discover how they work and what their main uses are.
Introduction to decision trees
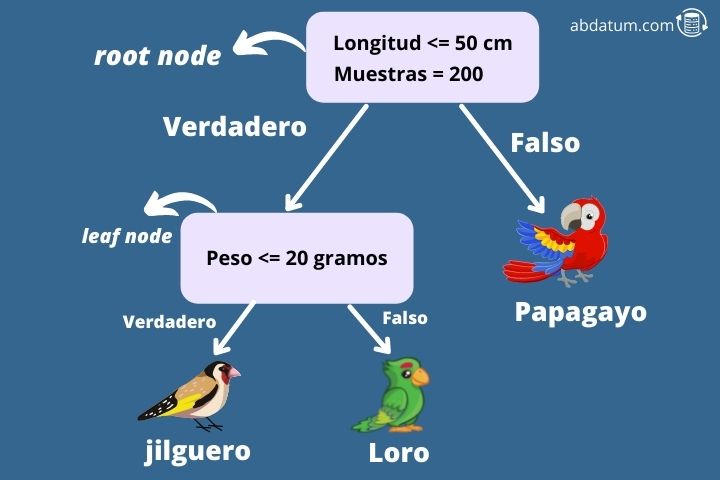
To better understand this algorithm, let's give an example. Imagine that we want to know, given some characteristics, whether a bird is a goldfinch, a lovebird or a parrot (typical 3-class multiclassification problem). To do this, we begin to build a decision tree from node zero.
The first node is known as the root node and in this case it asks if the bird's wings are less than 50 cm long. If so, the algorithm moves to its right child node. This type of node is called a leaf node.
The next node asks if the bird's weight is less than 20 grams. If not, the algorithm specifies that the bird species is a parrot. Alternatively, if it weighs less than 20 grams it is a goldfinch.
In this way we can determine to which class a certain entry in our dataset belongs. But how is a decision tree built?
The mission of the decision tree algorithm is to create subsets of the training data set that are separated by some of the characteristics that we have given as input information, in this case, for example, the length of the wings or the weight of the bird .
A metric is used in each node, which is called gini impurity for determine which of the characteristics gives us a greater degree of separation. The feature that allows us to most optimally separate the dataset is the one that will be used in that node as a separation criterion.
Advantages of decision tree algorithm
It is important to understand what advantages and disadvantages the use of these types of supervised autonomous learning algorithms brings us. Below you will find the highlights of the use of this type of model as well as its limitations.
- Non-linear machine learning methods that give a great flexibility to the model.
- The data needs little preparation since this algorithm does not need to scale the features so that they are at close values.
- They can combined to build more robust models. These are known as assemblers or ensemble methods.
- We can build both a classification model as a regression one.
- Easily understandable since you can graph the decision tree of each model and understand it visually, for example, using the Python library Graphviz.
Limitations of decision trees
- Decision trees have decision boundaries (decision boundaries) orthogonal so the results are rotation sensitive of the dataset data. This can lead to problems in the generalization of the model.
- It is a method very sensitive to small variations in the training data set.
- Very complex models can be built and given rise to what is known as overfitting or overfitting where the data fits the training data very well but The model does not generalize well. Techniques such as pruning can be used to reduce this effect.
- Finding the most optimal decision tree is a mathematical problem called NP-complete. These types of problems prevent the most optimal solution from being found, so heuristic methods are used with the aim of getting as close as possible to the most optimal answer for a given problem.
Joint learning or ensemble learning
Now that we roughly understand how decision trees work, we will give an introduction to much more powerful algorithms that make use of decision trees.
I have ensemble learning train different decision trees for different subsets of data of the training dataset. To predict a result, the answer is obtained for each of the trees and finally the result that has had the most votes is chosen.
Typically, joint learning methods are more used than separate decision trees since they improve the accuracy of predictions and decrease the overfitting or overfitting.
Some of the assembly methods Most popular ones that can use decision trees as predictors are:
- Bagging: This method consists of training different subsets of the training dataset with different predictors. If the same predictor can be used several times then the methodology is called Bagging. On the contrary, if sampling occurs without replacement then it is called pasting. An example of bagging used with decision tree predictors is the random forest.
- Boosting: Boosting methods aim to concatenate different predictors where each one must improve the result of the previous one. The most popular boosting algorithms are AdaBoost or Gradient Boosting. XGBoost is a popular library that uses gradient boosting using decision trees.