Shannon entropy


Shannon entropy is an important concept in information theory with multiple applications in computer science, telecommunications and, of course, deep learning.
A concept closely related to Shannon entropy is “crossentropy.” This measure is usually used as a loss function in multiple neural network architectures.
This article aims to give the reader a brief introduction to information theory and the measurement of entropy in relation to said theory. In addition, we will see other very important concepts such as cross entropy or Kullback-Leibler divergence.
Concept of entropy
The concept of entropy appears in many areas of science and technology. In statistical physics, entropy is considered the degree of disorder of a system.
However, this definition is imprecise. The real definition of entropy is the degree of information/misinformation we have about a system. That is, the more information we have, the less entropy.
Let's take an example. When water is at a temperature of -273.15 ºC (absolute zero) the molecules do not move at all. Therefore, it only has one possible configuration and the information we have about said system is maximum. Therefore, this ideal system would have an entropy of zero.
If we increase the temperature of the water, the molecules will adopt multiple configurations, decreasing the amount of information we can access and, therefore, increasing the entropy.
In information theory, entropy refers to the amount of information that an event or probability distribution provides us. We will go into more detail below.
Entropy in information theory
As we have seen, Shannon entropy measures the amount of information in a probability or event distribution. For example, let's imagine that we live in a city where it always rains. The information “it will rain tomorrow” does not give us much new information since it rains every day.
However, if the message says “Tomorrow it will be brightly sunny” it gives us much more information since it is an event that is unlikely to happen. Therefore, this last event has a higher entropy than the previous one.
Entropy is a basic concept in information theory. However, in machine learning and other fields of statistics such as variational inference, other related concepts such as cross entropy or Kullback-Leibler divergence (Relative Entropy) are more important.
Cross entropy or “cross-entropy”
Cross entropy measures the difference between two probability distributions of a set of events.
In many areas of artificial intelligence this measure is used as a cost function or loss function.
In the end, the goal of many deep learning tasks is to build a probability function on the variable of interest that is as close as possible to the real distribution. To know the difference between the inferred distribution and the real one (which comes from the training set), the cross-entropy measure is used.
At each iteration, the cross-entropy is minimized by reducing the error and each time obtaining a model that is as close as possible to the real probability distribution.
At a mathematical level, cross-entropy is defined as the entropy of the real distribution p plus the difference between the real distribution and the modeled one. If these two probability distributions are the same, then entropy and cross entropy are equivalent. This second term is known as Kullback-Leibler divergence, KL-divergence or relative entropy:
H(p,q) = H(p) + DKL(p|q)
In deep learning, as we will see in the next section, entropy remains constant. Therefore, minimizing cross entropy is equivalent to minimizing relative entropy.
Kullback–Leibler divergence or relative entropy
Another important concept is the Kullback-Leibler divergence. This measure is mathematically related to cross entropy.
Divergence = cross entropy – entropy
This measure, like the cross entropy, tells us how different the distribution generated by the model is from the real distribution.
In the context of machine learning and deep learning, Kullback-Leibler divergence and cross-entropy are equivalent since, as we see in the equation, the only thing that differentiates them is entropy. This entropy is defined on the real probability distribution, therefore, it does not change and we can ignore it.
Applications of Shannon entropy in Machine Learning
In machine learning, more specifically in classification problems, cross entropy is used as a cost function.
Let's imagine that we want to train a convolutional neural network that is capable of generating a multiclassifier that, given an image of an animal, tells us which animal the photo belongs to.
At the end of the architecture of a multiclassifier generated with a CNN (Convolutional Neural Network) we have a softmax function that indicates the probabilities that the photo has of belonging to each of the categories.
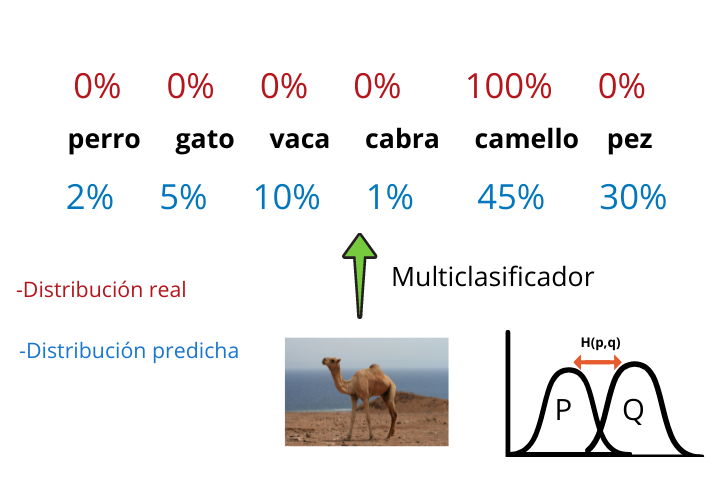
Finally, the label that has the highest probability is taken and the result is displayed.
This probability distribution generated by the multiclassifier is the modeled distribution q and the real results (which we have since we are working with supervised learning) form the real distribution p.
By constructing the cross entropy function and minimizing it at each iteration we will reduce the difference between both distributions and therefore our model will generate increasingly more realistic results.