Redes neuronales recurrentes


Dentro del campo del deep learning o aprendizaje profundo, existen muchas arquitecturas y morfologías de redes neuronales distintas. Cada una se especializa en un tipo de tarea en concreto.
Por ejemplo, las redes neuronales convolucionales tienen como característica que aceptan información codificada en tensores de 4 dimensiones, como son las imágenes, por lo que cuando tenemos que trabajar con datos de imagen haremos uso de ellas.
Para trabajar con texto, y en general, con datos de secuencias, la red neuronal más óptima son las que se conocen como redes neuronales recurrentes.
En el artículo de hoy daremos una introducción a las redes recurrentes, explicaremos como funcionan, los tipos que existen y que aplicaciones tienen en la actualidad.

Máster de machine learning, mejores másteres de España
¿Quieres aprender inteligencia artificial o machine learning? Te mostramos los mejores másteres tanto presencial como online de España. ¡No te lo puedes perder!
Ver artículo¿Qué son las redes neuronales recurrentes?
Las redes neuronales recurrentes o recurrent neural networks (RNN) es un tipo de red neuronal artificial especializada en procesar datos secuenciales o series temporales cuya arquitectura permite que la red obtenga memoria artificial.
Este tipo de red artificial ayuda a realizar predicciones de lo que sucederá en un futuro a partir de datos históricos. Por ejemplo, podemos usar las redes neuronales recurrentes para predecir el volumen de ventas de un cierto producto. Esto ayuda a predecir el stock necesario y ahorrar dinero.
También son muy útiles para analizar texto y generar de nuevo a partir de el ya existente. Existe una película que se rodó hace unos años cuyo guion fue generado por una inteligencia artificial que utilizaba este tipo de redes neuronales.
La arquitectura de este tipo de modelos permite que la inteligencia artificial pueda recordar y olvidar información. De esta forma, la IA es capaz de recordar el texto procesado hace decenas de frases y asociar conceptos con las nuevas frases que va analizando.
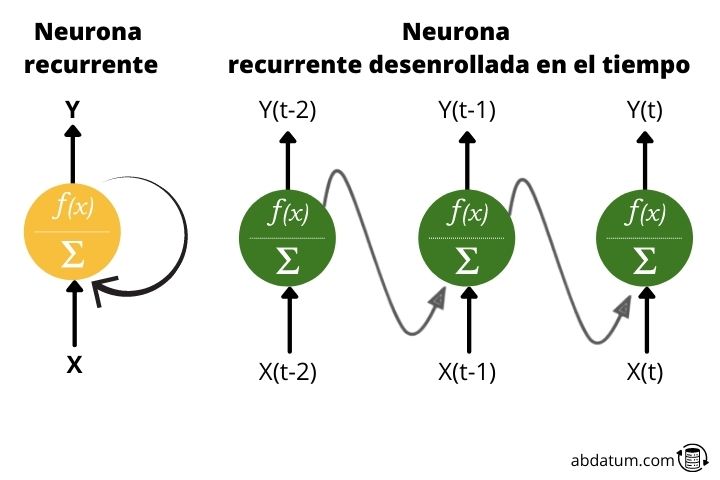
La neurona recurrente
Hemos visto que este tipo de redes tienen memoria. ¿Cómo lo consiguen?
Otros posts que te gustarán
Empecemos con lo básico. ¿Qué es una neurona recurrente?
Normalmente, cuando hablas de redes neuronales, las funciones de activación solo se mueven hacia una dirección: hacia adelante.
Una neurona recurrente transmite la información hacia adelante pero también tiene la característica de enviar la información hacia atrás. Por lo tanto, en cada paso, la neurona recurrente recibe datos de las neuronas anteriores, pero también recibe información de ella misma en el paso anterior.
A efectos prácticos, este tipo de conexiones cíclicas no son eficientes por lo que se establece un despliegue para generar una arquitectura sin ciclos, mucho más adecuado para aplicar las herramientas matemáticas de optimización.
Tipos de redes neuronales recurrentes
Existen distintas variaciones de redes neuronales recurrentes según el formato de los datos de entrada y de salida que queramos obtener.
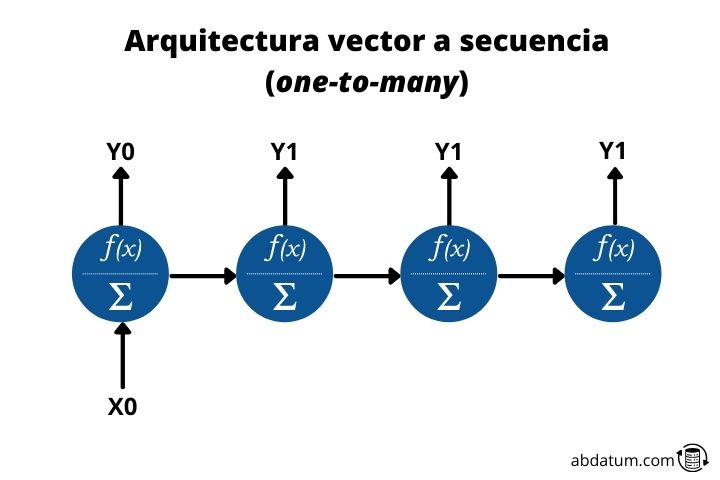
Vector a secuencia o one-to-many
Este tipo de arquitectura permite la entrada de un dato y la salida de muchos datos en forma de secuencia. De ahí viene el nombre inglés de one-to-many.
Un ejemplo sería un modelo que a partir de una imagen nos la pudiera describir. Por lo tanto, en la red entraría un único dato, en este caso la imagen y obtendríamos una secuencia de datos, el texto, que sería la descripción de la imagen.
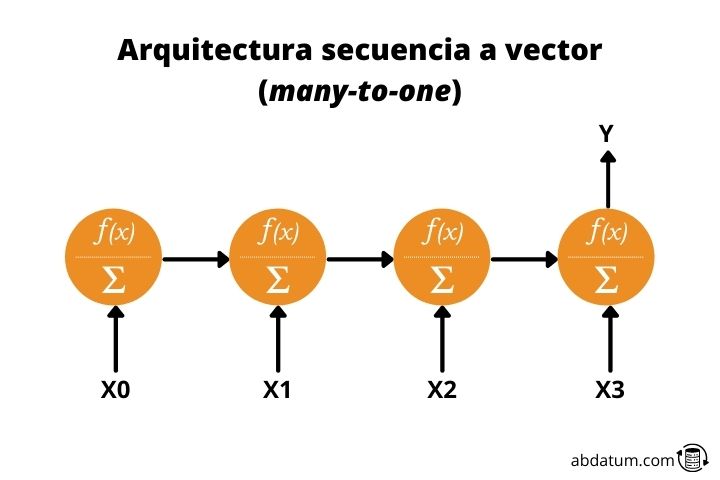
Secuencia a vector o many-to-one
Este tipo de arquitectura es justo el contrario de la anterior. Damos como valor de entrada una secuencia y obtenemos un dato único.
Por ejemplo, un modelo que recibiera una descripción de una imagen y creara dicha imagen seria una rede neuronal recurrente many-to-one.
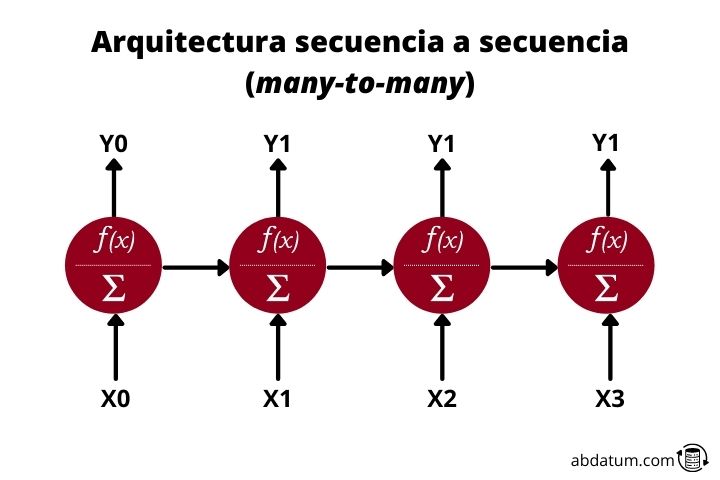
Secuencia a secuencia o many-to-many
Finalmente tenemos las redes recurrentes many-to-many. Esta arquitectura recibe datos secuenciales de entrada y crea datos secuenciales de salida. Un ejemplo muy claro son los traductores inteligentes.
Estos reciben un texto, por ejemplo, en castellano y genera un nuevo texto, por ejemplo, en inglés. También sirven para generar resúmenes de texto o para pasar texto a audio o audio a texto.
Celdas de memoria o memory cells
Cómo hemos visto en esquemas anteriores, la información fluye de una neurona a otra de un tiempo superior. Por lo tanto, los datos de entrada es una función de los datos de entrada en tiempos anteriores.
Toda la información nueva va añadiéndose al flujo de datos, hecho que permite que este tipo de redes tengan memoria. Resumiendo, las RNN tiene a cada timestep o paso de tiempo información de los tiempos anteriores, es decir, puede recordar lo visto anteriormente en la secuencia.
Esto permite, por ejemplo, que cuando se introduce un texto en la red neuronal recurrente, esta pueda relacionar conceptos distantes en la secuencia.
Problema de la memoria a corto plazo ( short-term memory )
La memoria de este tipo de redes es limitada, por lo que, es difícil la transmisión efectiva de información entre secuencias muy alejadas entre sí.
Esto es debido a lo que se conoce como desvanecimiento del gradiente o gradient vanishing .
Esto problema sucede cuando, durante el entrenamiento de la red neuronal recurrente, los pesos se hacen cada vez más pequeños, provocando que el gradiente también disminuya y que apenas se actualicen los pesos de la red, perdiendo la capacidad de aprendizaje del modelo.
Redes neuronales recurrentes LSTM y GRU
Para solucionar el problema de la memoria a corto plazo se crearon lo que se conocen como puertas o gates en inglés. Estas puertas son básicamente operaciones matemáticas como sumas o multiplicaciones que actúan como mecanismos para almacenar la información relevante y eliminar aquella que no tiene relevancia para el aprendizaje.
Los dos tipos de redes más importantes con estos mecanismos que permiten una memoria a más largo plazo son las LSTM ( Long-Short Term Memory ) y las GRU ( Gated Recurrent Units ).
LSTM ( Long-Short Term Memory )
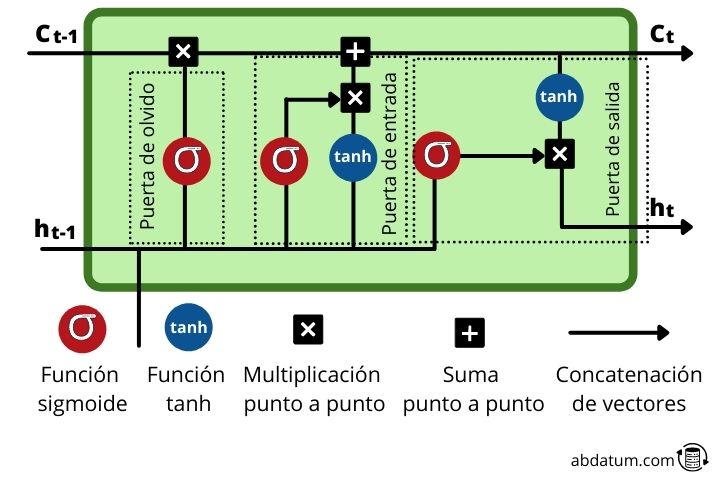
Las LSTM son un tipo de redes neuronales recurrentes donde cada célula de memoria o memory cell tiene un grupo de operaciones muy especificas que permiten controlar el flujo de información. Estas operaciones, llamadas puertas permiten decidir si cierta información es recordada u olvidada.
Dentro de la célula de memoria nueva información es añadida a la que proviene de secuencias anteriores, es decir, de pasos de tiempo previos. Como veremos, información relevante nueva es agregado al flujo gracias a una operación de adición.
Veamos estos mecanismos más detalladamente:
- Puerta de olvido o forget gate : Esta puerta decide que información permanece y cual se olvida. Esto se consigue con la función sigmoide la cual tiene un dominio de 0 a 1. Cuanto más cerca del 0 menos importante es y cuanto más cerca del 1 más importante es.
- Puerta de entrada o input gate : El papel de esta puerta consiste en actualizar el estado oculto (hidden state) de la célula. Para esta tarea, el nuevo input es añadido al estado oculto de un tiempo anterior. La cantidad de información que se conserva se controla con la función sigmoide transformando los valores entre 0 y 1. Cero significa que es poco importante y por tanto puede eliminarse. La unidad significa que es importante y que ese conocimiento debe permanecer.
- Puerta de salida o output gate : Esta puerta se encarga de decidir cual será el estado oculto de la célula en el timestep siguiente. Para ello hace uso de la función sigmoide y tanh.
- Función tanh : esta función que vemos repetidas veces dentro de las células de memoria tiene la función de comprimir los valores entre 1 y -1 para evitar que dichos valores incrementen mucho o disminuyan mucho y así evitar problemas del gradiente durante el entrenamiento que dificultarían el aprendizaje de la red.
GRU ( Gated Recurrent Units )
Las GRUs son neuronas recurrentes con una estructura algo diferente que las LSTM. Son más nuevas y eliminan algunas de las operaciones de las LSTM.
Las GRUs no emplean el estado de célula ( cell state ), solo usan el hidden state para la transferencia de información. Además, tienen 2 puertas o gates diferenciadas: la puerta de actualización o update gate y la puerta de reseteo o reset gate .
- Puerta de actualización : este tipo de puerta de las GRUs es parecida a la función de las puertas de olvido y de entrada de las LSTMs. Cuyo objetivo es mantener la información relevante y eliminar los datos que no son importantes.
- Puerta de reseteo : Esta puerta controla la cantidad de información que se olvida durante el aprendizaje de la red.
Cómo vemos, las GRUs tienen menos operaciones y por lo tanto son más rápidas de entrenar que las LSTMs.
A efectos prácticos las dos morfologías de red funcionan bien. Cual es mejor dependerá del tipo de problema y, por consiguiente, lo más recomendable es probar las 2 arquitecturas, tanto los GRUs como las LSTMs para determinar con cual se obtienen unos mejores resultados.
Aplicaciones de las recurrent neural networks
Existen múltiplos ejemplos de usos y aplicación de este tipo de redes neuronales. Seguidamente te mostramos algunos para que puedas hacerte una idea del poder que tienen las redes neuronales recurrentes.
Traductores inteligentes
Los traductores entrenados con inteligencia artificial hacen uso de este tipo de redes neuronales artificiales para poder generar texto traducido.
También pueden usarse para traducciones a tiempo real donde los datos de entrada es la voz del orador y los datos de salida es voz artificial con el texto traducido.
Este tipo de morfología de redes neuronales ha mejorado enormemente la calidad de los textos traducidos, ya que anteriormente, se hacia uso de funciones basadas en memoria.
Chatbots inteligentes
Las RNN también se usan para generar bots automáticos que sean capaces de contestar preguntas que puedan tener los posibles clientes. En muchas páginas web vemos un chat con el que podemos interactuar y hablar para resolver cuestiones sobre el producto.
Muchos de estos chats funcionan con inteligencias artificiales entrenadas específicamente para este tipo de función. Estos modelos normalmente son LSTMs o GRUs.
Predicción de ventas
Aparte de texto, también podemos emplear otro tipo de información secuencial como son las series temporales. Muchos comercios utilizan modelos de machine learning para llevar a cabo predicciones de venta y de esta forma ahorrar en stock.
Por lo tanto, las RNN también sirven para hacer predicciones de precios a partir de un histórico de datos de las ventas pasadas.
Asistentes virtuales
El último ejemplo es el de asistentes virtuales. Si tenemos aparatos apple sabremos que podemos pedirle acciones a Siri para que las ejecute. Lo mismo si tenemos Alexa, de Amazon.
Estos asistentes son capaces de interpretar ordenes con una gran variedad de idiomas diferente y llevar a cabo las acciones que le piden.
Para poder entender la información que se le transmite hacen uso de redes neuronales RNN.