Redes neuronales artificiales


El mundo de la inteligencia artificial ha evolucionado mucho durante esta última década. Este avance se debe mayoritariamente a la evolución de un tipo de algoritmo llamado red neuronal.
¿Qué son las redes neuronales?
La teoría de redes neuronales existe desde hace muchos años, de alrededor de los años 60. No obstante, no teníamos las herramientas matemáticas necesarias para poder aplicarlas de forma práctica en nuestro mundo hasta hace unos pocos años.
El objetivo de este tipo de redes, conocidas en inglés como neural networks , es intentar simular el funcionamiento de nuestro cerebro para crear un modelo que sea capaz de actuar como una inteligencia. Por lo tanto, podemos decir que:
Una red neuronal artificial es un modelo matemático formado por diversas operaciones que tiene como objetivo emular el comportamiento de nuestras neuronas para poder aprender a partir de la experiencia, es decir, de unos datos iniciales.

Ganar dinero con inteligencia artificial
¿Quieres saber cómo ganar dinero con la inteligencia artificial? En este artículo te mostramos algunas ideas de cómo puedes usar la IA para tu beneficio.
Ver artículoResumidamente, lo que hacen las redes neuronales o inteligencia artificial es imitar el aprendizaje humano. Nosotros todo que sabemos es gracias a la experiencia de nuestros años de vida. Cuando nacemos, nuestro cerebro está en blanco y a medida que experimentamos, este se va llenando de conocimiento y sabiduría.
Las redes neuronales funcionan de forma similar. Al inicializarse, están en blanco y no tienen información valiosa en su interior. No obstante, a medida que alimentamos la red de datos, esta va aprendiendo pudiendo tomar decisiones ella misma a partir de la experiencia, es decir, de los datos que le hemos dado.
El perceptrón: la unidad básica de la red
Podemos considerar el perceptrón como la unidad básica de una red neuronal . Matemáticamente es un clasificador binario linear que puede aprender a clasificar dos clases distintas.
Por ejemplo, si tenemos un grupo de imágenes de gatos y perros mezcladas, un perceptrón sería capaz de diferenciar una imagen de gato de una de un perro.
No obstante, es un modelo muy sencillo que actualmente solo se usa para explicar como funcionan las redes neuronales, que simplemente son muchos perceptrones unidos entre ellos.
Otros posts que te gustarán
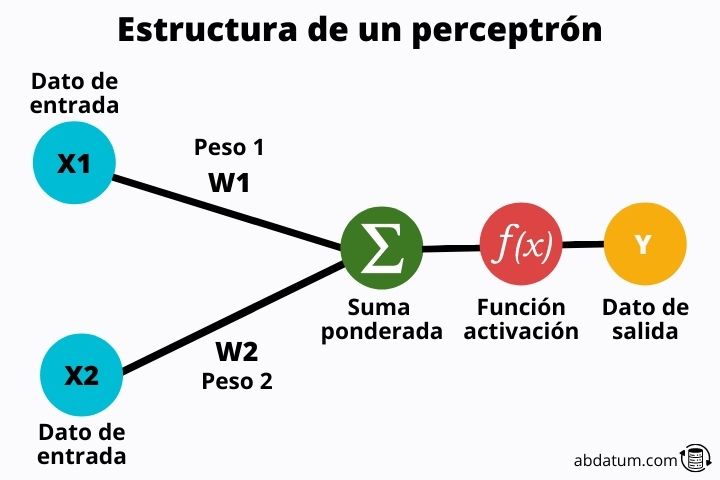
Veamos que partes tiene un perceptrón:
Valores de entrada
Estos valores son la información que entra dentro del perceptrón . Se trata de características de cada una de las clases a clasificar.
Por ejemplo, si estamos hablando de animales algunas de las características podrían ser el color de pelo, el color de los ojos, el número de patas, el tipo de pelo etc.
Estos valores se irán transformando a través de un conjunto de operaciones matemáticas.
Pesos de las entradas
Los pesos son valores aleatorios que se multiplican con los valores de entrada . Estos pesos, es a grandes rasgos lo que permite aprender a una red neuronal. Al principio son valores aleatorios, pero poco a poco, a medida que la red neuronal es entrada, estos son optimizados para dar los mejores resultados posibles.
Funciones de activación
Una vez las características se han multiplicado por los pesos se suman y el valor resultante se pasa por lo que se conoce función de activación.
Más adelante entraremos en detalle que es esta función, pero resumidamente, su misión es controlar el aprendizaje del perceptrón o más generalmente de la red neuronal.
Gracias a estas funciones, las redes neuronales son altamente flexibles y pueden aprender todo tipo de tareas.
Capas de las redes neuronales
Hemos visto, de forma general, que es un perceptrón. Ya podemos empezar con las redes neuronales artificiales.
Las neural networks son simplemente una combinación de muchos perceptrones. A partir de ahora, estos perceptrones los llamaremos neuronas.
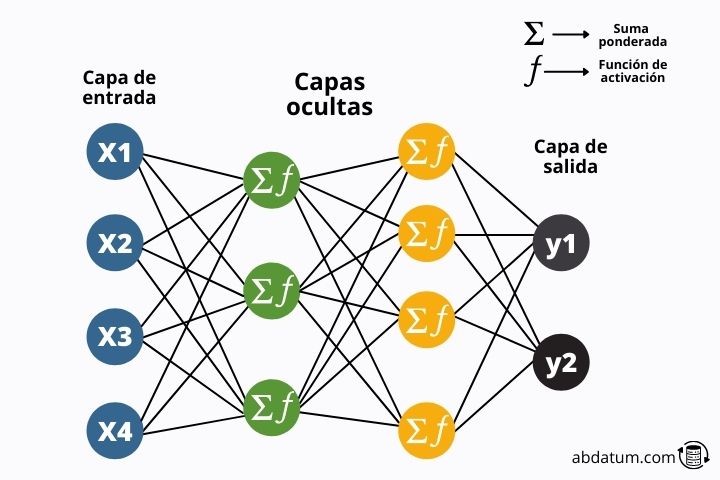
Por lo tanto, una red neuronal artificial es simplemente un conjunto de neuronas unidas entre ellas formando distintas capas .
En el siguiente esquema podemos ver la estructura típica de estos modelos matemáticos.
La información fluye a través de la red hasta llegar al final de esta donde se compara los resultados con la información real. Veámoslo en más detalle:
Entrenamiento de las redes neuronales
Las redes neuronales lo que hacen es transformar los valores de entrada en valores de salida gracias a múltiples operaciones matemáticas que albergan en su interior, como sumas o multiplicaciones.
Los valores de salida tienen que compararse con los valores reales. Por ejemplo, si la red neuronal nos dice que la imagen es un perro entonces tenemos que decirle si ha acertado o de lo contrario, ha fallado.
Esto se consigue gracias a la función de perdida o de coste (en inglés loss function ). Esta función matemática le indica a la red lo mucho o poco que se ha equivocado.
De esta forma, el algoritmo puede optimizar los pesos para minimizar la función de error. Esta minimización permitirá que la próxima vez los resultados se han mucho mejores.
Esto se hace iterativamente durante distintos ciclos. Estos ciclos reciben el nombre de épocas y el conjunto de operaciones que se llevan a cabo para minimizar la función de coste recibe el nombre de entrenamiento.
Por lo tanto, el entrenamiento de una red neuronal consiste en lo siguiente:
- Los pesos se inicializan de forma aleatoria en toda la red.
- Los datos de entrada son operados en la red multiplicándose con los pesos aleatorios y transformados por las funciones de activación.
- Los datos transformados llegan al final de la red y son comparados con los resultados reales.
- Se crea una función de coste que determina el grado de error de la red.
- Los pesos son ajustados para minimizar el error.
- Los datos vuelven a entrar en la red con los pesos optimizados y se repite este ciclo durante varias épocas hasta que el error sea mínimo.
Backpropagation o propagación hacia atrás
El algoritmo de backpropagation o propagación hacia atrás fue el héroe de la inteligencia artificial. Antes de su descubrimiento no había forma de entrenar las redes neuronales artificiales.
Como hemos mencionado anteriormente, se conoce la teoría desde hace décadas. No obstante, por la falta de recursos computacionales y de este algoritmo, las redes no podían ser entrenadas.
Este algoritmo permite minimizar todos los pesos de las redes, que pueden ser millones y millones, en un tiempo razonable aplicando diferentes métodos matemáticos del análisis funcional.
Se emplea la regla de la cadena de la diferenciación matemática de funciones para encontrar los valores que hacen que el error sea mínimo.
Minimizadores de la función de coste
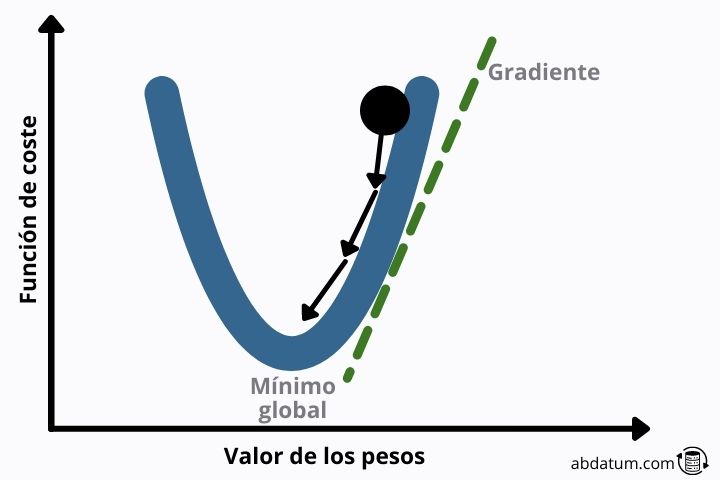
Existen múltiples algoritmos que permiten optimizar funciones matemáticas. El más conocido en el mundo de la inteligencia artificial es el descenso de gradiente.
Este método consiste en encontrar el vector que define el descenso más pronunciado para llegar antes a un mínimo local de la función.
Si la forma de la función de pérdida es cuadrática, este mínimo local es el mínimo global con lo que se evitan mucho de los problemas que veremos a continuación.
Problema de desvanecimiento del gradiente
En redes con muchas capas, el gradiente tiene que propagarse por todos los pesos de la red neuronal. Poco a poco este gradiente va haciéndose más y más pequeños.
A valores muy cercanos a cero, el gradiente ya no sirve para optimizar la red neuronal y, por lo tanto, el entrenamiento deja de hacerse.
Una de las mejores soluciones es utilizar lo que se conoce como skip conections . Esta arquitectura permite crear conexiones entre neuronas lejanas que no viene de la capa anterior.
De esta forma, la información puede fluir saltándose algunas neuronas evitando el problema del desvanecimiento del gradiente.
Problema del exploding gradient o gradiente explosivo
El problema del gradiente explosivo es el contrario de lo que hemos visto en la sección anterior. Algunos tipos de funciones de activación generan valores numéricos altos.
Esto puede derivar en valores muy altos de gradientes desestabilizando la red neuronal y generando predicciones muy poco precisas.
Uno de los métodos para evitar el gradiente explosivo se conoce como gradient clipping y consiste en reescalar el gradiente para que la norma del vector este dentro de un rango determinado.
Tipos de redes neuronales
Existen muchas arquitecturas distintas de redes neuronales. Dependiendo de como las conectemos y del tipo de operaciones que se lleven a cabo en su interior corresponderán a un tipo u otro.
Redes neuronales prealimentadas
Las redes neuronales prealimentadas o en ingles feed forward neural networks constituyen un tipo de arquitectura donde la información solo circula hacia adelante, no hay bucles ni conexiones entre neuronas de la misma capa.
Están formadas por la unión de diferentes perceptrones que son los encargados de realizar la transformación de los datos de entrada.
Este tipo de redes neuronales son las más sencillas y fueron las primeras en implementarse para llevar a cabo tareas de inteligencia artificial.
Redes neuronales convolucionales
Las redes convolucionales o también conocidas como convolutional neural networks (CNN) tienen una arquitectura óptima para trabajar con imágenes.
Los pesos de este tipo de red forman filtros que son capaces de detectar diferentes características de una foto, como podrían ser, sombras, bordes o la forma de un ojo humano.
Se aplican un gran número de filtros mientras la información fluye de capa en capa. Estos filtros son los responsables de clasificar la imagen al final del proceso.
En 2012 un modelo llamado ImageNet entrenado con este tipo de redes neuronales fue capaz de clasificar hasta 1000 objetos diferentes en un conjunto de un millón de imágenes.
En ese momento se vio el potencial de las CNN para llevar a cabo inteligencia artificial con imágenes de todo tipo.
Redes neuronales recurrentes
Las redes neuronales recurrentes son un tipo de red que puede formar ciclos, es decir, una neurona puede estar conectada con ella misma.
Gracias a la utilización de la recurrencia, redes recurrentes como LSTM ( Long-Short Term Memory ) o las GRUs ( Gated Recurrent Unit ) son capaces de tener memoria y recordar secuencias que han analizado previamente.
Esto permite que estas redes artificiales sean muy eficaces analizando datos que tengan una estructura en secuencia. Un ejemplo son los textos.
Una frase puede referirse a un suceso anterior, que haya pasado unas líneas de texto atrás. Gracias a la recurrencia, estás redes son capaces de recordar y relacionar secuencias de texto lejanas entre ellas.
Otro tipo de aplicación de redes recurrentes es el análisis de series temporales. Muchas empresas utilizan esta arquitectura para hacer predicciones de ventas de productos basado en una secuencia de ventas del año anterior.