Banco de dados relacional, conheça o modelo relacional e alguns exemplos

Vivemos numa era em que a gestão de dados é essencial para a maioria das empresas e negócios do mundo.
As maiores empresas de tecnologia do mundo como Netflix, Amazon, Google ou Facebook utilizam esta informação para dar aos utilizadores o que querem ver.
Hoje vamos falar sobre
- 1. O que são bancos de dados relacionais?
- 2. Características dos bancos de dados relacionais
- 3. Modelo de relacionamento entre entidades
- 4. Exemplos de bancos de dados relacionais
- 5. Vantagens e desvantagens dos bancos de dados relacionais
- 6. Diferença entre banco de dados não relacional e banco de dados relacional
Para fazer isso, eles precisam armazenar milhões e milhões de dados de maneira ordenada para que, quando necessário, possam ser extraídos de forma rápida e eficiente.
Mas... Como e onde é armazenada toda esta enorme quantidade de informação?
Bem, sim, você acertou. Todas essas informações são armazenadas em uma rede de computadores conectados entre si por meio do que conhecemos como bancos de dados (BBDD) .
Existem diferentes tipos de bancos de dados, mas o mais utilizado e o que está conosco há mais tempo chama-se banco de dados relacional .
Neste artigo você aprenderá em que consistem e como funcionam. Além disso, daremos algumas dicas sobre como começar a gerenciá-los.
O que são bancos de dados relacionais?
Um banco de dados relacional é um tipo de banco de dados que utiliza o modelo relacional para representar e criar uniões entre diferentes dados para que possam ser consultados e atualizados utilizando a linguagem SQL ( Linguagem de consulta estruturada ).
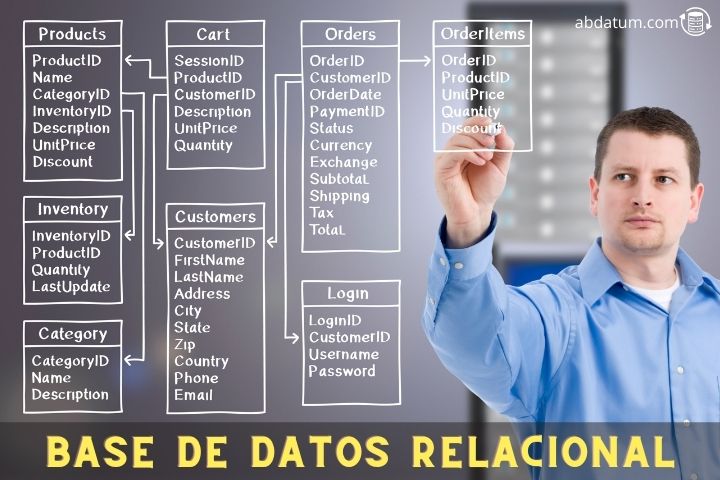
As informações são armazenadas em tabelas onde cada uma possui diversas linhas. Cada um deles possui um rótulo exclusivo chamado chave primária.
Ao mesmo tempo, a tabela também contém colunas chamadas atributos. Cada linha ou registro na tabela possui valores de atributos associados. Vejamos um exemplo fácil:
Imagine que queremos cadastrar os usuários do nosso site. Cada usuário tem um nome, um sobrenome, um e-mail e um endereço.
Estas características de cada um dos usuários definem as diferentes colunas da tabela. Portanto, cada usuário é uma linha diferente, ou seja, um registro na tabela.
Mencionamos anteriormente que cada um dos registros deve ter um campo único e exclusivo. Desta forma podemos diferenciar cada usuário sem nenhum problema.
Nesse caso seria o e-mail, pois dois usuários podem ter o mesmo nome, até mesmo o mesmo sobrenome e podem morar na mesma rua, mas nunca podem ter o mesmo e-mail.
Portanto, o email do usuário seria a chave primária e com isso poderíamos identificar rapidamente o nosso usuário.
Na imagem a seguir podemos ver um diagrama de como seria nossa tabela de usuários dentro de um banco de dados relacional.
Características dos bancos de dados relacionais
Este tipo de banco de dados possui características diferenciadas que o tornam um poderoso data warehouse.
Uma das principais características é evitar duplicação. Ter elementos duplicados pode levar a uma interpretação incorreta dos dados.
Para evitar esse problema, cada registro é identificado exclusivamente por uma chave primária. Além disso, as tabelas também devem ter um nome exclusivo.
Outro ponto importante é a integridade dos dados. Esses tipos de modelos mantêm grande integridade graças à exatidão e integridade das informações, evitando que os dados sejam corrompidos e que novas entradas inválidas sejam adicionadas ao banco de dados.
Outra peculiaridade são as relações que podem ser estabelecidas entre diferentes tabelas. Esses relacionamentos permitem unir e extrair dados de diferentes tabelas como se fossem uma só.
Esses relacionamentos são realizados usando o que é conhecido como chaves primárias e chaves estrangeiras. Mais tarde veremos em que consistem esses tipos de operações.
Modelo de relacionamento de entidade
Um banco de dados relacional pode se tornar muito complexo e ter muitos relacionamentos entre uma ampla variedade de tabelas. Por isso, é importante, antes de começar, projetar qual estrutura e arquitetura ela terá.
Para representar a estrutura podemos usar o que é conhecido como modelo entidade-relacionamento. Este tipo de representação possui alguns elementos que nos permitem definir com precisão todos os elementos da nossa base de dados relacional. Vamos vê-los:
Entidade
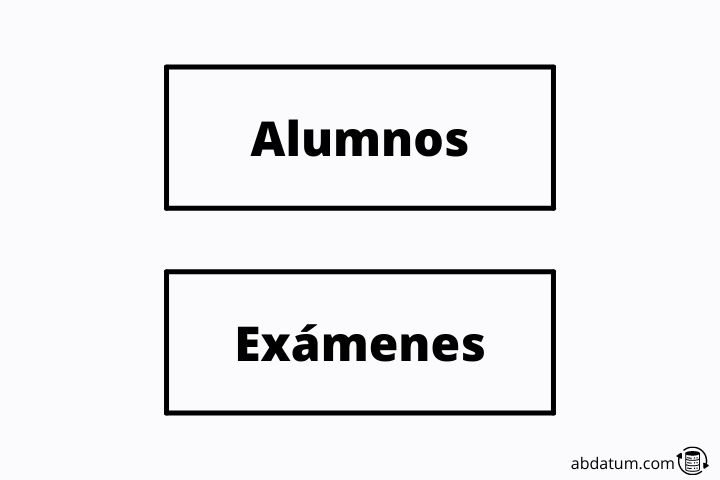
Entidades são representações de objetos onde cada um possui características específicas. As identidades são as tabelas que geramos no banco de dados. Para dar um exemplo, imagine um instituto onde temos muitos alunos.
Uma entidade seriam os “alunos” que armazenam as informações de cada um deles. Outra entidade poderia ser os “exames” onde é guardada a informação sobre os exames realizados durante o ano letivo.
Outra identidade poderia ser o dever de casa contendo informações sobre os diferentes trabalhos que os alunos tiveram que realizar em casa.
Essas identidades são representadas como retângulos no esquema ou diagrama que geramos para determinar a estrutura do BD.
Atributos
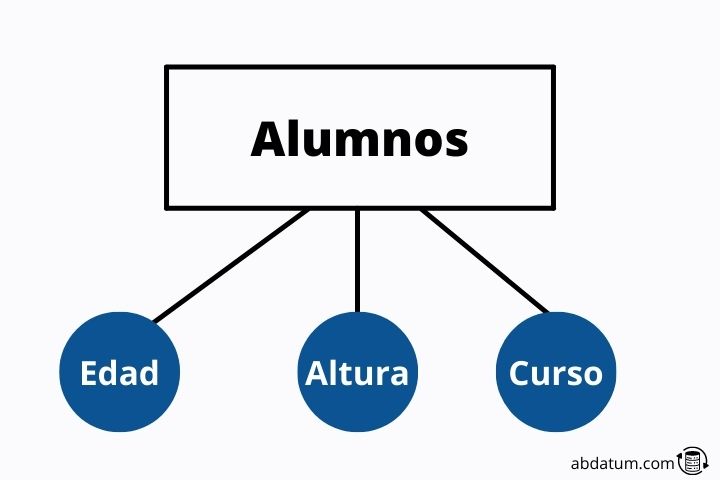
Os atributos (colunas) são as características que definem cada elemento da identidade. Por exemplo, os atributos do aluno podem ser: idade, altura, nota, número de exames aprovados ou número de exames reprovados.
Cada um dos atributos nos fornece informações sobre cada aluno que contém a identidade.
Os atributos são representados no diagrama como círculos pendurados em identidades (símbolos retangulares).
Relações
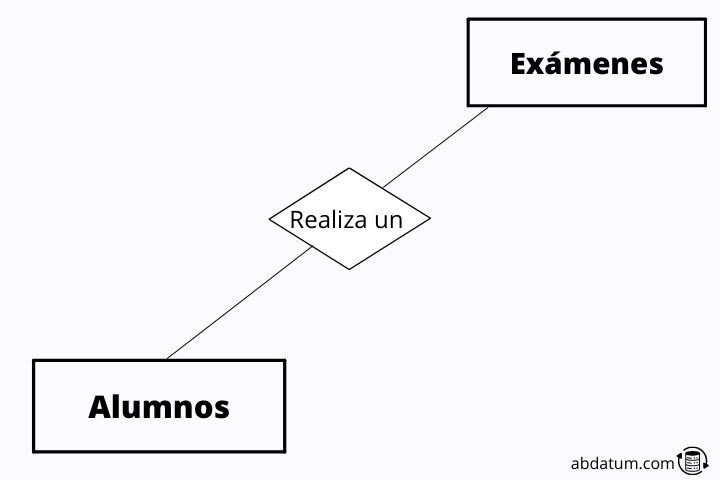
Os relacionamentos representam as dependências que existem entre diferentes tabelas ou identidades. Por exemplo, cada aluno realiza exames diferentes durante o ano, portanto, cada aluno da tabela ou identidade “alunos” estará relacionado a um ou mais exames da tabela ou identidade “exames”.
Ao estabelecer esta relação podemos ver as notas que um aluno obteve nas diferentes provas realizadas durante o ano letivo.
Esses relacionamentos são representados no diagrama do modelo entidade-relacionamento como losangos que são unidos às identidades por linhas.
Chaves
- Chave primária : é uma chave que identifica uma entrada da tabela como exclusiva. Por exemplo, na nossa base de dados escolar seria um número de identificação único para cada aluno da escola.
- Chave estrangeira : Este campo seria, por exemplo, o identificador do aluno na tabela do exame. Nesta tabela a identificação do aluno não será única, pois o aluno realiza mais de um exame. Portanto, a chave estrangeira não deve ser única, mas deve estar relacionada à chave primária única da tabela a que se refere, neste caso, a tabela estudantes.
Exemplos de bancos de dados relacionais
Mais do que exemplos de bancos de dados, deveríamos falar de exemplos de gerenciadores de bancos de dados relacionais.
Um sistema gerenciador de banco de dados é um software cuja função é armazenar, manipular e extrair todo tipo de informação do banco de dados.
Alguns gestores amplamente conhecidos no mundo tecnológico são os seguintes:
1. MySQL
MySQL é o sistema de gerenciamento de dados de código aberto mais popular do planeta.
Algumas das vantagens do MySQL são que ele é gratuito, é um banco de dados muito rápido que permite consultar dados com muita rapidez e precisão, é compatível com a maioria dos sistemas operacionais e possui um ambiente de criptografia e segurança.
Sem dúvida, MySQL é uma opção perfeita para implementar em ferramentas ou aplicações web.
2. MariaDB
Este gerenciador é muito semelhante ao anterior, pois foi implementado por um dos desenvolvedores do MySQL. Esses dois são muito semelhantes em funcionalidade.
No entanto, o MariaDB adiciona algumas melhorias, como a capacidade de realizar consultas complexas que podem ser armazenadas em cache no computador para melhorar a velocidade quando a consulta for realizada novamente.
MariaDB permite o uso de estruturas mais complexas como hierarquias de gráficos . No entanto, na maioria das situações, ambos os gestores são válidos.
3. PostgreSQL
PostgreSQL, geralmente chamado de Postgres, é um gerenciador de dados de código aberto orientado a objetos que funciona com o modelo relacional. Sua linguagem SQL é um pouco diferente dos gerenciadores anteriores.
Está em conformidade com o modelo ACID, fornecendo dados armazenados com Atomicidade, Consistência, Integridade e Durabilidade. Isso evita que as informações armazenadas sejam corrompidas.
Vantagens e desvantagens dos bancos de dados relacionais
Alguns vantagens de usar bancos de dados relacionais são as seguintes:
- Maturidade : Este tipo de banco de dados está conosco há muito tempo, por isso possui uma grande comunidade e muita documentação sobre o assunto.
- Linguagem SQL : Todos os bancos de dados relacionais funcionam com um gerenciador que permite extrair informações usando o que é conhecido como SQL ( Linguagem de consulta estruturada ). Isso permite a unificação e a utilização de um banco de dados com diferentes gestores.
- Simplicidade : Um de seus pontos fortes é a simplicidade de uso. SQL é uma linguagem muito semelhante à linguagem natural humana, então com pouco tempo você pode aprender a usar esse tipo de gerenciadores.
Diferença entre banco de dados não relacional e banco de dados relacional
As bancos de dados relacionais Eles são uma coleção de objetos organizados em tabelas com linhas e colunas. Uma linguagem de programação conhecida como SQL (Structured Query Language) é usada para consultar, adicionar e modificar informações no banco de dados.
Este tipo de banco de dados utiliza o modelo relacional e estabelece diferentes relacionamentos entre as tabelas existentes em todo o banco de dados.
As bancos de dados não relacionais ou NOSQL Não estabelecem relacionamentos e não utilizam tabelas para armazenar informações. Possuem uma estrutura flexível que permite salvar todos os tipos de dados: gráficos, documentos, pares chave-valor, etc.
Os bancos de dados NOSQL são otimizados para armazenar grandes quantidades de informações não estruturadas. Uma de suas vantagens sobre os relacionais é a grande escalabilidade.