O que é overfitting


Overfitting, ou mais conhecido por sua tradução para o inglês, overfitting, é uma propriedade do modelo estatístico que nos diz que ele não será capaz de generalizar adequadamente para outros dados com os quais não foi treinado.
O overfitting acontece quando na construção de um modelo de aprendizado de máquina o método utilizado dá muita flexibilidade aos parâmetros e acaba gerando um modelo que se ajusta perfeitamente aos dados que foram treinados, mas não é capaz de realizar a função básica de um modelo. : ser capaz de generalizar para novas informações.
O overfitting é um dos principais problemas da aprendizagem autônoma e da inteligência artificial em geral. Se não conseguirmos detectar este problema, nosso modelo será de qualidade muito baixa, mesmo que tenha bons resultados de previsão no conjunto de treinamento.
Existem diferentes maneiras de detectar e evitar overfitting no modelo de previsão. A maioria dessas técnicas consiste em reduzir a complexidade do modelo para que ele se ajuste menos ao conjunto de treinamento e seja capaz de generalizar para novas observações.
Como detectar overfitting ou overfitting
Como vimos, diagnosticar o nosso modelo deve ser uma etapa obrigatória antes de colocá-lo em produção. Caso contrário, as previsões feitas poderão ser imprecisas e o nosso projeto poderá não funcionar como deveria. Abaixo mostramos algumas verificações que podemos fazer para detectar o nível de overfitting ou underfitting que nosso modelo estatístico sofre.
Troca de polarização-variância
É importante conhecer o conceito de equilíbrio entre preconceito e variação no mundo do aprendizado de máquina. No aprendizado de máquina, nosso objetivo é ser capaz de construir uma função f' que seja o mais próxima possível da função original f que modele o comportamento de nossos dados.
Quando treinamos um modelo, basicamente o que estamos fazendo é construir a função f' a partir dos dados que usamos como entrada.
A variância representa o quanto a função f' varia ao alterar o conjunto de treinamento. Se mudar muito, dizemos que o modelo estatístico tem uma variância alta, então com certeza sofre de overfitting, pois é capaz de modelar perfeitamente os dados de treinamento, mas ao generalizar para dados que nunca viu, falha.
Podemos definir o viés como o oposto. Se ao usar diferentes conjuntos de treinamento a função f' permanecer praticamente a mesma, então o modelo possui baixa variância e alto viés. Isso indica que temos underfitting, então o modelo é muito simples e não se ajusta bem aos dados de treinamento ou validação.
O que devemos tentar ao construir nossos modelos é um equilíbrio entre variância e viés.
Na próxima seção ensinaremos uma técnica com a qual você poderá detectar visualmente esses problemas.
Curvas de aprendizagem
Curvas de aprendizagem ou curvas de aprendizagem em inglês são um dos melhores métodos para diagnosticar nosso modelo para possíveis problemas de overfitting (alta variância) ou underfitting (alto viés).
Em um gráfico de curva de aprendizado típico, temos uma métrica de erro no eixo das ordenadas, por exemplo, o MSE (Erro Quadrático Médio) e o eixo das coordenadas possui tamanhos diferentes do conjunto de treinamento.
As funções de aprendizagem nos dirão como o erro do modelo varia com o tamanho do conjunto de dados de aprendizagem.
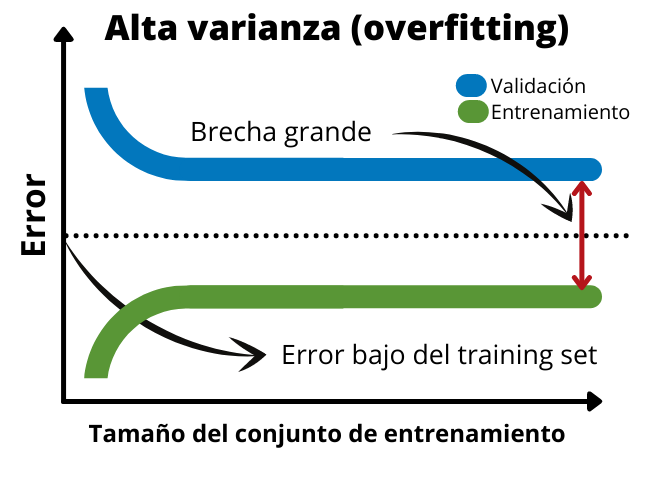
No caso de overfitting ou alta variância, o gráfico mostrará como existe uma grande lacuna entre os dados de validação e os dados de treinamento. Isso ocorre porque o modelo se ajusta muito bem aos dados de treinamento, portanto o erro no conjunto de treinamento será muito baixo. Contudo, não é possível generalizar. Por esse motivo, o erro no conjunto de validação será muito maior. No gráfico a seguir podemos ver as curvas de aprendizado típicas de um modelo com overtraining.
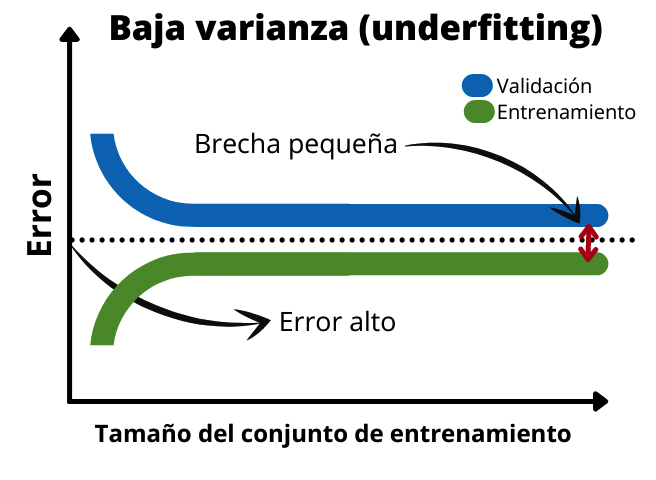
Quando temos um viés alto ou um ajuste insuficiente, a lacuna entre as duas funções é muito pequena. Além disso, o erro do conjunto de validação e do conjunto de treinamento é alto. Isso indica que é um modelo muito simples que não se ajusta bem aos dados. Neste caso seria necessário adicionar mais dados de treinamento ou aumentar o tempo de treinamento do modelo.
Como resolver o sobreajuste
O overfitting é um problema muito comum e os cientistas de dados devem lidar constantemente com isso. A seguir mostraremos algumas das técnicas mais utilizadas pelos cientistas de dados ao redor do mundo para eliminar o overfitting e melhorar a generalização do modelo.
1. Simplificação do modelo
O primeiro passo é reduzir a complexidade do modelo. A forma de fazer isso dependerá do método de aprendizado de máquina utilizado.
Nas redes neurais podemos reduzir o número de camadas ou neurônios. Também podemos usar técnicas de regularização, como abandono ou parada antecipada.
No caso de utilizarmos árvores de decisão podemos utilizar uma técnica conhecida como poda.
Noutros casos, como Support Vector Machines (SVM) ou técnicas de regressão, a regularização dos modelos é conseguida através dos seus hiperparâmetros, que acrescentam restrições, limitando a flexibilidade.
2. Técnicas de aumento de dados
Essas técnicas consistem em gerar novos dados a partir de dados existentes. Por exemplo, num conjunto de imagens, algumas transformações que podemos aplicar que gerariam novas amostras são translações, rotações, dimensionamento, filtros ou alterações de iluminação.
3. Elimine o ruído do conjunto de treinamento
Em alguns casos, o overfitting pode ser devido à má limpeza dos dados. Ao recebermos os dados brutos, devemos realizar o que é conhecido como limpeza de dados para eliminar outliers, padronizar os dados e excluir informações que possam adicionar ruído à nossa modelagem.
Ao realizar processos de limpeza de dados podemos reduzir a variância, melhorando os resultados finais.
4. Obtenha mais observações
Obter mais dados pode ajudar a resolver o problema. No entanto, também é possível que este não seja o caso e teremos que utilizar uma das outras metodologias desta secção.
5. Transferir técnicas de aprendizagem
Em alguns casos, o problema de overfitting pode ser devido aos poucos dados que temos. Também é possível que mais dados não possam ser adquiridos aumentando o conjunto de dados.
Neste ponto podemos recorrer a outros tipos de soluções como a aprendizagem por transferência, ou mais conhecida como aprendizagem por transferência. Esta solução consiste em adotar um modelo já treinado e funcional que desempenha função semelhante e treiná-lo novamente com nosso pequeno conjunto de dados.
Implementação em Python
Neste artigo do blog abdatum vimos o que é overfitting ou overfitting, como detectá-lo e como resolvê-lo. Também explicamos que as curvas de aprendizado são um dos melhores métodos para diagnosticar o modelo de aprendizado de máquina. Como criamos curvas de aprendizado?
Podemos fazer isso manualmente. No entanto, o pacote Python sklearn inclui o curva de aprendizado dentro de model_selection. Nesta função temos que passar o estimador que utilizaremos para construir o modelo e o conjunto de dados de treinamento.
A partir das informações retornadas, podemos representar graficamente as curvas usando a biblioteca matplotlib.