Qué es un árbol de decisión


Los árboles de decisión son un algoritmo matemático estadístico usado en el mundo de la ciencia de datos y del machine learning para realizar predicciones. Es un método de aprendizaje autónomo supervisado que puede emplearse para problemas tanto de clasificación como regresión.
Si quieres aprender más sobre estos métodos quédate y descubre cómo funcionan y cuáles son sus principales usos.
Introducción a los árboles de decisión
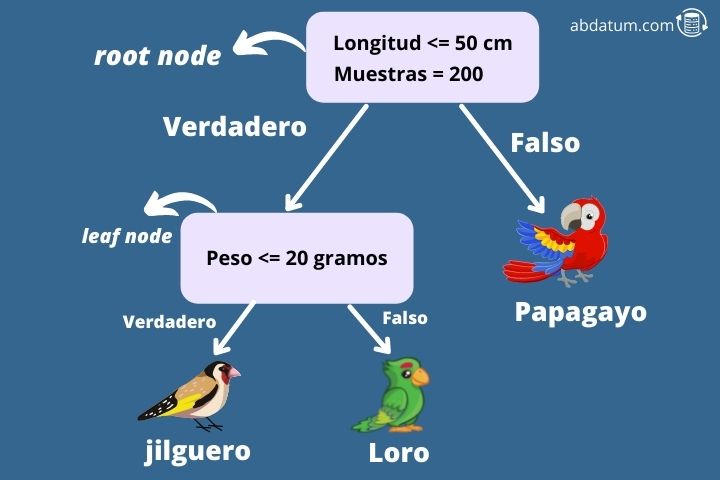
Para entender mejor este algoritmo vamos a poner un ejemplo. Imagina que queremos saber, dadas unas características, si un pájaro es un jilguero, un agaporni o un papagayo (típico problema de multiclasificación de 3 clases). Para ello empezamos a construir un árbol de decisión desde el nodo cero.
El primer nodo se conoce como el nodo raíz (root node) y en este caso se pregunta si las alas del pájaro tienen una longitud menor de 50 cm. De ser así el algoritmo se mueve hacia su nodo hijo de la derecha. Este tipo de nodo se denomina nodo hoja (leaf node).

Redes neuronales artificiales
Las redes neuronales artificiales son el algoritmo principal de las mejores inteligencias artificiales. Entra y aprende que son y cómo funcionan.
Ver artículoEl siguiente nodo se pregunta si el peso del pájaro es menor a 20 gramos. De no ser así el algoritmo especifica que la especie de pájaro es un loro. Alternativamente, si pesa menos de 20 gramos se trata de un jilguero.
De esta forma podemos determinar a qué clase pertenece una determinada entrada de nuestro dataset. ¿Pero cómo se construye un árbol de decisión?
La misión del algoritmo de árboles de decisión es crear subconjuntos del conjunto de datos de entrenamiento que están separados por alguna de las características que hemos dado como información de entrada, en este caso, por ejemplo, la longitud de las alas o el peso del pájaro.
En cada nodo se utiliza una métrica, que recibe el nombre de gini impurity para determinar cuál de las características nos da un grado mayor de separación. La feature que nos permite separar de forma más óptima el dataset es la que se usará en ese nodo como criterio de separación.
Ventajas del algoritmo de árbol de decisión
Es importante entender que ventajas y desventajas nos aporta el uso de estos tipos de algoritmos de aprendizaje autónomo supervisado. Seguidamente encontrarás los puntos más destacados del uso de este tipo de modelos al igual que sus limitaciones.
Otros posts que te gustarán
- Métodos de machine learning no lineales que dan una gran flexibilidad al modelo.
- Los datos necesitan de poca preparación ya que este algoritmo no necesita escalar los features para que se encuentren en valores próximos.
- Pueden combinarse para construir modelos más robustos. Estos se conocen como ensambladores o ensemble methods.
- Podemos construir tanto un modelo de clasificación como uno de regresión.
- Fácilmente entendible ya que se puede graficar el árbol de decisión de cada modelo y comprenderlo de forma visual, por ejemplo, usando la librería de Python Graphviz.
Limitaciones de los árboles de decisión
- Los árboles de decisión tienen límites de decisión (decision boundaries) ortogonales por lo que los resultados son sensibles a la rotación de los datos del dataset. Esto puede conllevar problemas en la generalización del modelo.
- Es un método muy sensible a pequeñas variaciones en el conjunto de datos de entrenamiento.
- Pueden construirse modelos muy complejos y que den lugar lo que se conoce como overfitting o sobreajuste donde los datos se adaptan muy bien a los datos de entrenamiento pero el modelo no generaliza bien. Pueden usarse técnicas como pruning para disminuir este efecto.
- Encontrar el árbol de decisión más óptimo es un problema matemático que recibe el nombre de NP-completo. Este tipo de problemas impiden que se pueda encontrar la solución más óptima por lo que se emplean métodos heurísticos con el objetivo de acercarse cuanto más mejor a la respuesta más óptima para un determinado problema.
Aprendizaje conjunto o ensamble learning
Ahora que ya entendemos a grandes rasgos cómo funcionan los árboles de decisión, daremos una introducción a unos algoritmos mucho más potentes que hacen uso de árboles de decisión.
El ensamble learning entrena distintos árboles de decisión para diferentes subconjuntos de datos del training dataset. Para predecir un resultado, se obtiene la respuesta para cada uno de los árboles y finalmente se elige el resultado que más votos ha tenido.
Normalmente, los métodos de aprendizaje conjunto son más usados que los árboles de decisión por separado ya que mejoran la exactitud de las predicciones y disminuyen el overfitting o sobreajuste.
Algunos de los ensamble methods más populares que pueden usar árboles de decisión como predictores son:
- Bagging: este método consiste en entrenar diferentes subconjuntos del dataset de entrenamiento con distintos predictores. Si un mismo predictor se puede usar varias veces entonces la metodología se llama Bagging. Al contrario, si el muestreo se da sin reemplazo entonces recibe el nombre de pasting. Un ejemplo de bagging usado con predictores de árboles de decisión es el random forest.
- Boosting: los métodos de boosting tienen como objetivo concatenar diferentes predictores donde cada uno debe mejorar el resultado del anterior. Los algoritmos de boosting más populares son AdaBoost o Gradient Boosting. XGBoost es una popular librería que utiliza el gradient boosting empleando árboles de decisión.