Réseaux de neurones récurrents


Dans le domaine de l'apprentissage en profondeur ou apprentissage profond, il existe de nombreuses architectures et morphologies de réseaux neuronaux différentes. Chacun se spécialise dans un type de tâche spécifique.
Par exemple, les réseaux de neurones convolutifs ont la particularité d'accepter des informations codées dans des tenseurs à 4 dimensions, comme des images, donc lorsque nous devrons travailler avec des données d'image, nous les utiliserons.
Pour travailler avec du texte, et en général avec des données de séquence, les réseaux de neurones les plus optimaux sont ceux appelés réseaux de neurones récurrents.
Dans l'article d'aujourd'hui, nous donnerons une introduction aux réseaux récurrents, nous expliquerons comment ils fonctionnent, les types qui existent et quelles sont leurs applications actuellement.
Que sont les réseaux de neurones récurrents ?
Les réseaux de neurones récurrents (RNN) sont un type de réseau de neurones artificiels spécialisé dans le traitement de données séquentielles ou de séries temporelles dont l'architecture permet au réseau d'obtenir une mémoire artificielle.
Ce type de réseau artificiel permet de prédire ce qui se passera dans le futur sur la base de données historiques. Par exemple, nous pouvons utiliser des réseaux de neurones récurrents pour prédire le volume des ventes d'un certain produit. Cela permet de prévoir le stock nécessaire et d’économiser de l’argent.
Ils sont également très utiles pour analyser du texte et en générer de nouveaux à partir de textes existants. Il existe un film tourné il y a quelques années dont le scénario a été généré par une intelligence artificielle utilisant ce type de réseaux neuronaux.
L’architecture de ce type de modèle permet à l’intelligence artificielle de mémoriser et d’oublier des informations. De cette manière, l'IA est capable de mémoriser le texte traité il y a des dizaines de phrases et d'associer des concepts aux nouvelles phrases qu'elle analyse.
Le neurone récurrent
Nous avons vu que ces types de réseaux ont de la mémoire. Comment l’obtiennent-ils ?
Commençons par les bases. Qu'est-ce qu'un neurone récurrent ?
Généralement, lorsque l’on parle de réseaux de neurones, les fonctions d’activation ne se déplacent que dans une seule direction : vers l’avant.
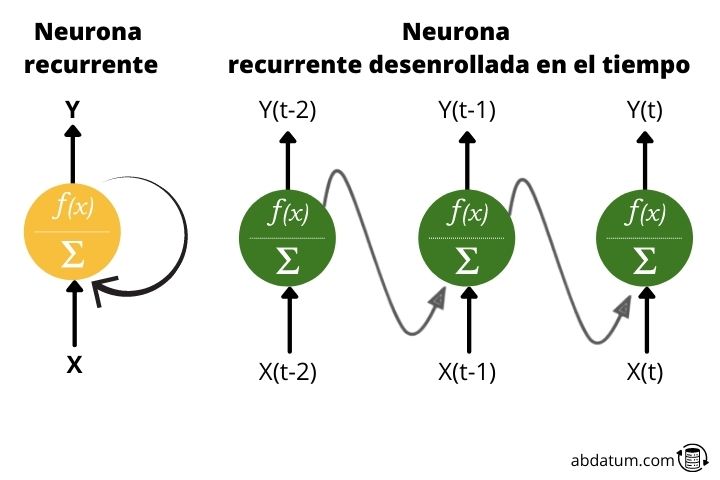
Un neurone récurrent transmet des informations vers l’avant mais a également la caractéristique d’envoyer des informations vers l’arrière. Ainsi, à chaque étape, le neurone récurrent reçoit des données des neurones précédents, mais reçoit également des informations de lui-même à l’étape précédente.
Pour des raisons pratiques, ce type de connexions cycliques n'est pas efficace, c'est pourquoi un déploiement est établi pour générer une architecture sans cycle, beaucoup plus adaptée à l'application d'outils d'optimisation mathématique.
Types de réseaux de neurones récurrents
Il existe différentes variantes de réseaux de neurones récurrents en fonction du format des données d'entrée et de sortie que l'on souhaite obtenir.
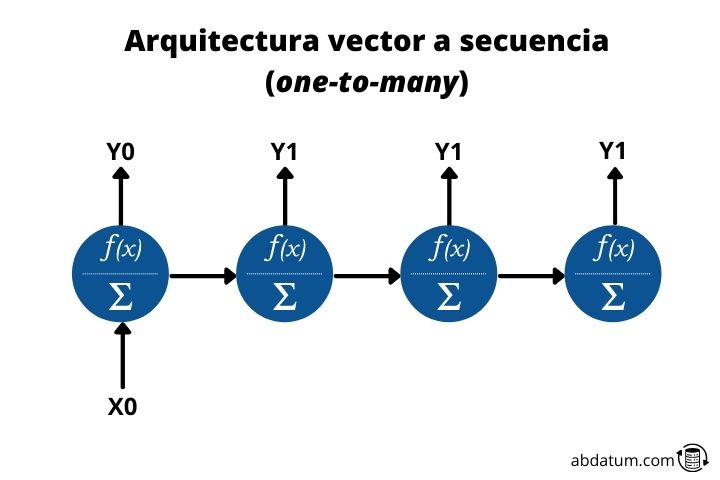
Vecteur à séquencer ou un à plusieurs
Ce type d'architecture permet l'entrée d'une donnée et la sortie de plusieurs données en séquence. C'est de là que vient le nom anglais one-to-many.
Un exemple serait un modèle qui pourrait nous le décrire à partir d’une image. Ainsi, une seule donnée entrerait dans le réseau, en l’occurrence l’image, et on obtiendrait une séquence de données, le texte, qui serait la description de l’image.
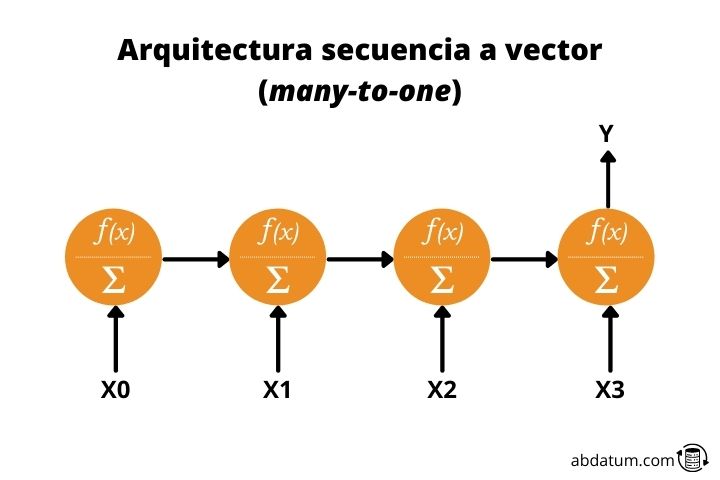
Séquence au vecteur ou plusieurs à un
Ce type d’architecture est tout le contraire du précédent. Nous donnons une séquence comme valeur d’entrée et obtenons une donnée unique.
Par exemple, un modèle qui a reçu une description d'une image et créé ladite image serait un réseau neuronal récurrent plusieurs-à-un.
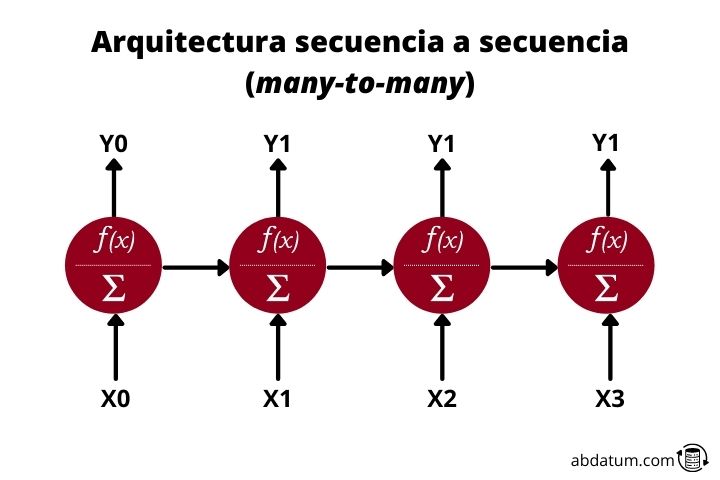
Séquence à séquence ou plusieurs à plusieurs
Enfin, nous avons plusieurs à plusieurs réseaux récurrents. Cette architecture reçoit des données d'entrée séquentielles et crée des données de sortie séquentielles. Un exemple très clair est celui des traducteurs intelligents.
Ils reçoivent un texte, par exemple en espagnol, et génèrent un nouveau texte, par exemple en anglais. Ils sont également utilisés pour générer des résumés de texte ou pour convertir du texte en audio ou de l'audio en texte.
Cellules mémoire ou cellules mémoire
Comme nous l’avons vu dans les schémas précédents, l’information circule d’un neurone à l’autre sur une période de temps plus longue. Par conséquent, les données d’entrée sont fonction des données d’entrée des instants précédents.
Toutes les nouvelles informations sont ajoutées au flux de données, ce qui permet à ce type de réseaux de disposer de mémoire. En bref, les RNN disposent d’informations sur les instants précédents à chaque pas de temps, c’est-à-dire qu’ils peuvent se souvenir de ce qui a été vu précédemment dans la séquence.
Cela permet, par exemple, que lorsqu'un texte est introduit dans le réseau neuronal récurrent, il puisse relier des concepts distants dans la séquence.
Problème de mémoire à court terme ( mémoire à court terme )
La mémoire de ce type de réseaux est limitée, ce qui rend difficile la transmission efficace d'informations entre des séquences très éloignées les unes des autres.
Cela est dû à ce que l'on appelle l'évanouissement par gradient ou disparition du dégradé .
Ce problème se produit lorsque, pendant l'entraînement du réseau neuronal récurrent, les poids deviennent de plus en plus petits, ce qui entraîne une diminution également du gradient et que les poids du réseau sont à peine mis à jour, perdant ainsi la capacité d'apprentissage du modèle.
Réseaux de neurones récurrents LSTM et GRU
Pour résoudre le problème de la mémoire à court terme, ce que l'on appelle les portes ou portes en anglais. Ces portes sont essentiellement des opérations mathématiques telles que l’addition ou la multiplication qui agissent comme des mécanismes pour stocker les informations pertinentes et éliminer les informations qui ne sont pas pertinentes pour l’apprentissage.
Les deux types de réseaux les plus importants dotés de ces mécanismes permettant une mémoire à plus long terme sont les LSTM ( Mémoire à long terme ) et le GRU ( Unités récurrentes fermées ).
LSTM ( Mémoire à long terme )
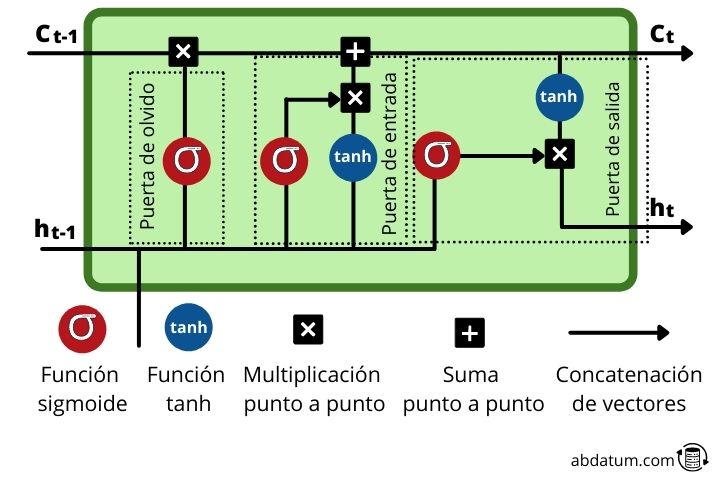
Les LSTM sont un type de réseaux neuronaux récurrents dans lesquels chaque cellule mémoire ou cellule mémoire Il dispose d'un groupe d'opérations très spécifiques qui permettent de contrôler le flux d'informations. Ces opérations, appelées portes, nous permettent de décider si certaines informations sont mémorisées ou oubliées.
Dans la cellule mémoire, de nouvelles informations s'ajoutent à celles provenant des séquences précédentes, c'est-à-dire des pas de temps précédents. Comme nous le verrons, de nouvelles informations pertinentes sont ajoutées au flux grâce à une opération d’ajout.
Examinons ces mécanismes plus en détail :
- Porte de l'oubli ou oublier la porte : Cette porte décide quelles informations restent et lesquelles sont oubliées. Ceci est réalisé avec la fonction sigmoïde qui a un domaine de 0 à 1. Plus elle est proche de 0, moins elle est importante et plus elle est proche de 1, plus elle est importante.
- porte d'entrée ou porte d'entrée : Le rôle de cette porte est de mettre à jour l'état caché de la cellule. Pour cette tâche, le nouveau saisir il s'ajoute à l'état caché d'un temps antérieur. La quantité d'informations conservées est contrôlée avec la fonction sigmoïde, transformant les valeurs entre 0 et 1. Zéro signifie qu'elle n'a pas d'importance et peut donc être éliminée. L'unité signifie que c'est important et que la connaissance doit demeurer.
- porte de sortie ou porte de sortie : Cette porte est chargée de décider quel sera l'état caché de la cellule dans le pas de temps suivant. Pour ce faire, il utilise les fonctions sigmoïde et tanh.
- fonction tanh : cette fonction que l'on voit à plusieurs reprises au sein des cellules mémoire a pour fonction de compresser les valeurs entre 1 et -1 pour éviter que ces valeurs n'augmentent trop ou ne diminuent trop et ainsi éviter les problèmes de gradient lors de l'entraînement qui le feraient difficile d'apprendre la grille.
GRU ( Unités récurrentes fermées )
Les GRU sont des neurones récurrents avec une structure quelque peu différente de celle des LSTM. Ils sont plus récents et éliminent certaines des opérations des LSTM.
Les GRU n'utilisent pas l'état de la cellule ( état de la cellule ), ils utilisent uniquement le état caché pour le transfert d'informations. De plus, ils ont 2 portes ou portes différencié : la porte de mise à jour ou porte de mise à jour et la porte de réinitialisation ou réinitialiser la porte .
- Porte de mise à niveau : Ce type de porte GRU est similaire à la fonction des portes d'oubli et d'entrée des LSTM. Dont l’objectif est de garder les informations pertinentes et d’éliminer les données qui ne sont pas importantes.
- réinitialiser la porte : Cette porte contrôle la quantité d'informations oubliées lors de l'apprentissage du réseau.
Comme nous le voyons, les GRU ont moins d’opérations et sont donc plus rapides à former que les LSTM.
Pour des raisons pratiques, les deux morphologies de réseau fonctionnent bien. La meilleure dépendra du type de problème et, par conséquent, il est préférable d’essayer les deux architectures, à la fois les GRU et les LSTM, pour déterminer laquelle obtient les meilleurs résultats.
Applications du réseaux de neurones récurrents
Il existe de multiples exemples d'utilisations et d'applications de ce type de réseaux de neurones. Ci-dessous, nous vous en montrons quelques-uns afin que vous puissiez avoir une idée de la puissance des réseaux de neurones récurrents.
Traducteurs intelligents
Les traducteurs formés à l'intelligence artificielle utilisent ce type de réseaux de neurones artificiels pour générer du texte traduit.
Ils peuvent également être utilisés pour des traductions en temps réel où les données d'entrée sont la voix du locuteur et les données de sortie sont une parole artificielle avec le texte traduit.
Ce type de morphologie de réseau neuronal a considérablement amélioré la qualité des textes traduits, puisqu'auparavant, des fonctions basées sur la mémoire étaient utilisées.
Chatbots intelligents
Les RNN sont également utilisés pour générer des robots automatisés capables de répondre aux questions que peuvent se poser les clients potentiels. Sur de nombreuses pages Web, nous voyons un chat avec lequel nous pouvons interagir et parler pour résoudre des questions sur le produit.
Beaucoup de ces chats fonctionnent avec une intelligence artificielle spécialement formée pour ce type de fonction. Ces modèles sont normalement des LSTM ou des GRU.
Prédiction des ventes
Outre le texte, nous pouvons également utiliser d'autres types d'informations séquentielles telles que des séries chronologiques. De nombreuses entreprises utilisent des modèles de apprentissage automatique pour réaliser des prévisions de ventes et ainsi économiser du stock.
Par conséquent, les RNN sont également utilisés pour effectuer des prévisions de prix basées sur les données historiques des ventes passées.
Assistants virtuels
Le dernier exemple concerne les assistants virtuels. Si nous avons des appareils Apple, nous saurons que nous pouvons demander à Siri des actions à exécuter. Pareil si nous avons Alexa, d'Amazon.
Ces assistants sont capables d'interpréter les commandes dans différentes langues et d'effectuer les actions demandées.
Afin de comprendre les informations transmises, ils utilisent les réseaux de neurones RNN.