Réseaux de neurones artificiels


Le monde de l’intelligence artificielle a beaucoup évolué au cours de la dernière décennie. Cette avancée est principalement due à l’évolution d’un type d’algorithme appelé réseau de neurones.
Que sont les réseaux de neurones ?
La théorie des réseaux de neurones existe depuis de nombreuses années, depuis les années 1960. Cependant, nous ne disposions pas des outils mathématiques nécessaires pour pouvoir les appliquer pratiquement dans notre monde jusqu'à il y a quelques années.
L'objectif de ce type de réseaux, connu en anglais sous le nom de les réseaux de neurones , tente de simuler le fonctionnement de notre cerveau pour créer un modèle capable d'agir comme une intelligence. On peut donc dire que :
Un réseau de neurones artificiels est un modèle mathématique composé de diverses opérations qui vise à émuler le comportement de nos neurones afin d'apprendre de l'expérience, c'est-à-dire des données initiales.
En bref, ce que font les réseaux de neurones ou l’intelligence artificielle, c’est imiter l’apprentissage humain. Tout ce que nous savons est dû à l'expérience de nos années de vie. À notre naissance, notre cerveau est vide et, au fur et à mesure de nos expériences, il se remplit de connaissances et de sagesse.
Les réseaux de neurones fonctionnent de la même manière. Une fois initialisés, ils sont vides et ne contiennent aucune information précieuse. Cependant, à mesure que nous alimentons le réseau de données, celui-ci apprend et est capable de prendre lui-même des décisions basées sur l'expérience, c'est-à-dire à partir des données que nous lui avons fournies.
Le perceptron : l'unité de base du réseau
On peut considérer le perceptron comme l'unité de base d'un réseau neuronal . Mathématiquement, c'est un classificateur binaire linéaire qui peut apprendre à classer deux classes différentes.
Par exemple, si nous avons un groupe d’images de chats et de chiens mélangés, un perceptron serait capable de différencier une image de chat de celle d’un chien.
Il s’agit cependant d’un modèle très simple qui n’est actuellement utilisé que pour expliquer le fonctionnement des réseaux de neurones, qui sont simplement de nombreux perceptrons reliés entre eux.
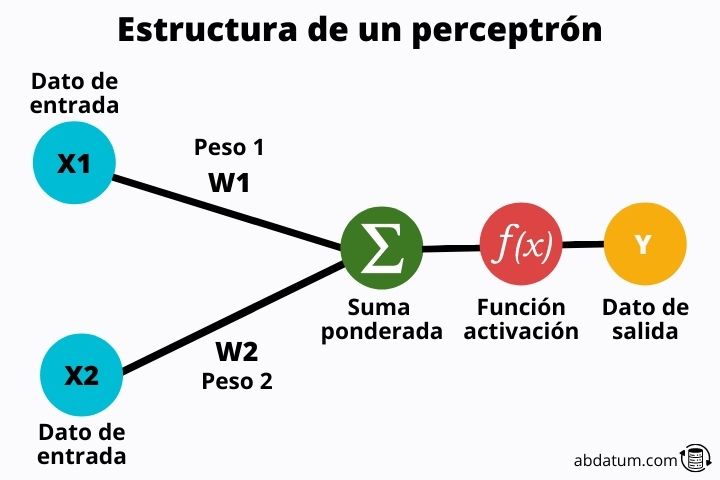
Voyons quelles sont les parties d'un perceptron :
Valeurs d'entrée
Ces valeurs sont les informations qui entrent dans le perceptron . Ce sont des caractéristiques de chacune des classes à classer.
Par exemple, si nous parlons d’animaux, certaines caractéristiques pourraient être la couleur des cheveux, la couleur des yeux, le nombre de pattes, le type de cheveux, etc.
Ces valeurs seront transformées grâce à un ensemble d'opérations mathématiques.
Poids des billets
Les poids sont valeurs aléatoires multipliées par les valeurs d'entrée . Ces poids sont en gros ce qui permet à un réseau neuronal d’apprendre. Au début, ce sont des valeurs aléatoires, mais au fur et à mesure que le réseau neuronal est saisi, celles-ci sont optimisées pour donner les meilleurs résultats possibles.
Fonctions d'activation
Une fois les caractéristiques multipliées par les poids, elles sont ajoutées et la valeur résultante passe par ce que l'on appelle la fonction d'activation.
Plus tard, nous détaillerons ce qu'est cette fonction, mais en résumé, sa mission est contrôler l'apprentissage du perceptron ou plus généralement du réseau de neurones.
Grâce à ces fonctions, les réseaux de neurones sont très flexibles et peuvent apprendre tous types de tâches.
Couches de réseau neuronal
Nous avons vu, de manière générale, qu'il s'agit d'un perceptron. Nous pouvons désormais commencer par les réseaux de neurones artificiels.
Le les réseaux de neurones Ils sont simplement une combinaison de nombreux perceptrons. Désormais, nous appellerons ces perceptrons des neurones.
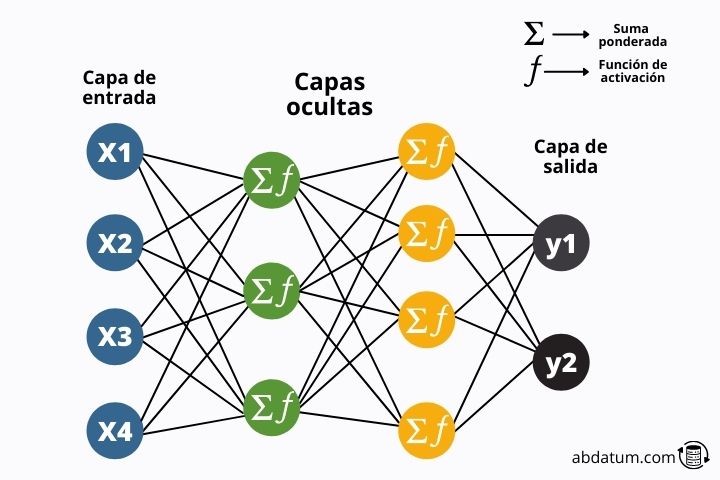
Un réseau de neurones artificiels est donc simplement un ensemble de neurones réunis formant différentes couches .
Dans le diagramme suivant, nous pouvons voir la structure typique de ces modèles mathématiques.
L'information circule à travers le réseau jusqu'à atteindre la fin du réseau où les résultats sont comparés aux informations réelles. Regardons cela plus en détail :
Entraînement des réseaux de neurones
Ce que font les réseaux de neurones, c'est transformer les valeurs d'entrée en valeurs de sortie grâce aux multiples opérations mathématiques qu'ils contiennent, comme l'addition ou la multiplication.
Les valeurs de sortie doivent être comparées aux valeurs réelles. Par exemple, si le réseau neuronal nous dit que l’image est un chien, nous devons lui dire si elle est correcte ou fausse.
Ceci est réalisé grâce au fonction de perte ou de coût (en anglais fonction de perte ). Cette fonction mathématique indique au réseau dans quelle mesure il a commis une erreur.
De cette manière, l’algorithme peut optimiser les poids pour minimiser la fonction d’erreur. Cette minimisation permettra aux résultats d'être bien meilleurs la prochaine fois.
Cela se fait de manière itérative au cours de différents cycles. Ces cycles sont appelés époques et l'ensemble des opérations effectuées pour minimiser la fonction de coût est appelé formation.
Par conséquent, la formation d’un réseau de neurones comprend les éléments suivants :
- Les poids sont initialisés de manière aléatoire sur tout le réseau.
- Les données d'entrée sont exploitées sur le réseau en multipliant avec les poids aléatoires et transformées par les fonctions d'activation.
- Les données transformées arrivent au bout du réseau et sont comparées aux résultats réels.
- Une fonction de coût est créée pour déterminer le degré d'erreur dans le réseau.
- Les poids sont ajustés pour minimiser les erreurs.
- Les données rentrent dans le réseau avec les poids optimisés et ce cycle est répété pendant plusieurs époques jusqu'à ce que l'erreur soit minime.
Rétropropagation
L’algorithme de rétropropagation était le héros de l’intelligence artificielle. Avant sa découverte, il n’existait aucun moyen de former des réseaux de neurones artificiels.
Comme nous l’avons mentionné précédemment, la théorie est connue depuis des décennies. Cependant, faute de ressources informatiques et de cet algorithme, les réseaux n’ont pas pu être entraînés.
Cet algorithme nous permet de minimiser tous les poids des réseaux, qui peuvent être des millions et des millions, dans un temps raisonnable en appliquant différentes méthodes mathématiques d'analyse fonctionnelle.
La règle de chaîne de différenciation mathématique des fonctions est utilisée pour trouver les valeurs qui rendent l'erreur minimale.
Minimiseur de fonction de coût
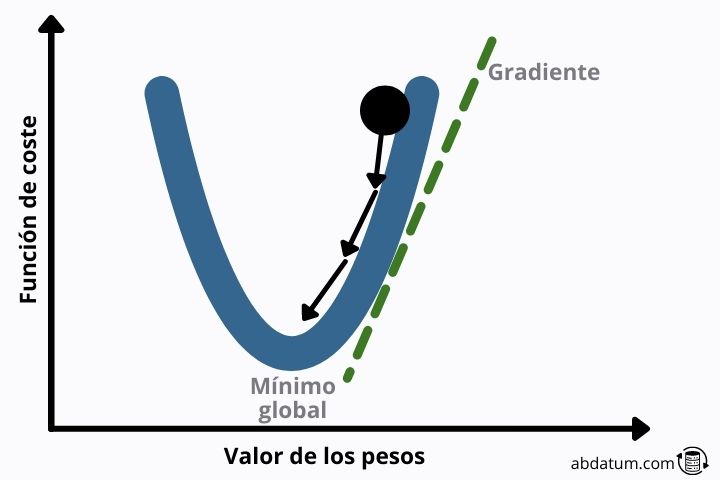
Il existe plusieurs algorithmes qui vous permettent d'optimiser les fonctions mathématiques. La plus connue dans le monde de l’intelligence artificielle est la descente de gradient.
Cette méthode consiste à trouver le vecteur qui définit la descente la plus raide pour atteindre plus tôt un minimum local de la fonction.
Si la forme de la fonction de perte est quadratique, ce minimum local est le minimum global, ce qui évite bon nombre des problèmes que nous verrons ci-dessous.
Problème de fondu de dégradé
Dans les réseaux comportant plusieurs couches, le gradient doit se propager à travers tous les poids du réseau neuronal. Petit à petit, ce gradient devient de plus en plus petit.
À des valeurs très proches de zéro, le gradient ne sert plus à optimiser le réseau neuronal et donc l'entraînement s'arrête.
L'une des meilleures solutions consiste à utiliser ce qu'on appelle sauter les connexions . Cette architecture permet de créer des connexions entre neurones distants qui ne proviennent pas de la couche précédente.
De cette manière, les informations peuvent circuler en sautant certains neurones, évitant ainsi le problème de l’évanouissement progressif.
Problème de dégradé explosif ou gradient explosif
Le problème du gradient explosif est à l’opposé de ce que nous avons vu dans la section précédente. Certains types de fonctions d'activation génèrent de grandes valeurs numériques.
Cela peut conduire à des valeurs de gradient très élevées, déstabilisant le réseau neuronal et générant des prédictions très inexactes.
L'une des méthodes permettant d'éviter le gradient explosif est connue sous le nom de découpage en dégradé et consiste à redimensionner le gradient pour que la norme du vecteur se situe dans une certaine plage.
Types de réseaux de neurones
Il existe de nombreuses architectures différentes de réseaux de neurones. Selon la manière dont on les connecte et le type d'opérations effectuées à l'intérieur, ils correspondront à un type ou à un autre.
Réseaux de neurones à action directe
Réseaux de neurones pré-alimentés ou en anglais réseaux de neurones à rétroaction Ils constituent un type d'architecture où l'information circule uniquement vers l'avant, il n'y a pas de boucles ni de connexions entre les neurones d'une même couche.
Ils sont formés par l’union de différents perceptrons chargés de transformer les données d’entrée.
Ce type de réseaux de neurones est le plus simple et a été le premier à être mis en œuvre pour réaliser des tâches d'intelligence artificielle.
Réseaux de neurones convolutifs
Les réseaux convolutifs, également appelés réseaux de neurones convolutifs (CNN), ont une architecture optimale pour travailler avec des images.
Les poids de ce type de réseau forment des filtres capables de détecter différentes caractéristiques d'une photo, comme les ombres, les bords ou la forme d'un œil humain.
Un grand nombre de filtres sont appliqués à mesure que les informations circulent d’une couche à l’autre. Ces filtres sont chargés de classer l'image à la fin du processus.
En 2012, un modèle appelé ImageNet entraîné avec ce type de réseaux de neurones était capable de classer jusqu'à 1 000 objets différents dans un ensemble d'un million d'images.
À cette époque, on voyait le potentiel des CNN pour réaliser une intelligence artificielle avec des images de tous types.
Réseaux de neurones récurrents
Les réseaux neuronaux récurrents sont un type de réseau qui peut former des cycles, c'est-à-dire qu'un neurone peut être connecté à lui-même.
Grâce à l'utilisation de la récurrence, les réseaux récurrents tels que LSTM ( Mémoire à long terme ) ou les GRU ( Unité récurrente fermée ) sont capables de mémoire et se souviennent des séquences qu’ils ont préalablement analysées.
Cela permet à ces réseaux artificiels d’être très efficaces pour analyser des données ayant une structure séquentielle. Un exemple est les textes.
Une phrase peut faire référence à un événement antérieur, survenu il y a quelques lignes de texte. Grâce à la récurrence, ces réseaux sont capables de mémoriser et de relier entre elles des séquences de textes distantes.
Un autre type d’application réseau récurrente est l’analyse de séries chronologiques. De nombreuses entreprises utilisent cette architecture pour effectuer des prévisions de ventes de produits basées sur une séquence de ventes de l'année précédente.