O que é um lago de dados

A extração e o armazenamento de dados são cruciais hoje em dia em todos os setores. Essas informações armazenadas podem posteriormente ser usadas para melhorar uma aplicação, negócio ou empresa.
Introdução aos data lakes ou Data Lakes
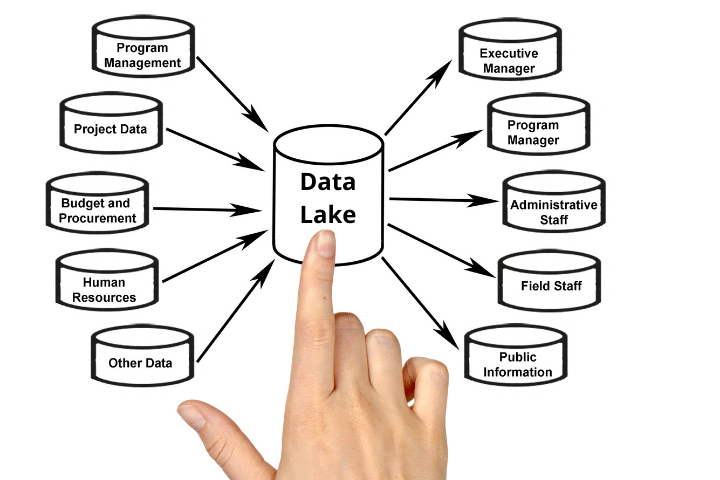
Um data lake é um repositório projetado para armazenar todos os tipos de dados sem nenhum esquema pré-determinado, ou seja, podemos salvá-los brutos sem pré-processá-los.
Essas tecnologias fazem uso do procedimento ELT (Extract, Load and Transform), que se refere à extração de dados de uma fonte original e carregá-los na fonte final, que é o data lake. Posteriormente, aqueles que interessam podem ser filtrados, agrupados ou selecionados.
Uma das vantagens de usar data lakes em relação a outras arquiteturas é a velocidade de ingestão de dados, uma vez que eles não precisam ser limpos antes de serem salvos. Além disso, também não perdemos informações, pois todas ficam armazenadas.
Características do Data Lake
Ambiente distribuído
Muitos data lakes oferecem suporte ao armazenamento distribuído de dados, aumentando a capacidade de ingestão de dados e tornando-os altamente escaláveis.
Obtenção de dados em tempo real
Por não ter um esquema pré-definido, a recolha de dados é muito rápida, permitindo que os dados sejam recuperados e processados em tempo real.
Suporta todos os tipos de formatos
Os data lakes permitem formatos estruturados, semiestruturados e não estruturados. Este recurso permite que todos os tipos de informações sejam salvos nele, independentemente do seu formato.
Camadas em um data lake
Vimos que as informações armazenadas em data lakes são dados brutos. No entanto, podem existir camadas superiores onde estes dados são processados para fornecer ao cliente ou utilizador a informação de que necessita.
Abaixo mostramos algumas das camadas típicas presentes em uma arquitetura de data lake.
- Ingestão de dados : esta etapa é opcional e envolve algumas verificações nas informações antes de armazená-las no data lake. Por exemplo, você pode adicionar filtros ou realizar processos de criptografia para maior segurança.
- Salvou : Nesta parte os dados estruturados, semiestruturados ou não estruturados são armazenados sem qualquer transformação prévia.
- Acusação : Depois de salvos, pode ser necessário criar uma camada onde os dados sejam processados e transformados para mostrá-los a determinados usuários. Neste ponto, os processos de qualidade dos dados para garantir a integridade, confiabilidade e relevância dos dados ingeridos.
Diferenças entre Data Lake e Data Warehouse
Os data warehouses só permitem que os dados sejam armazenados com uma estrutura anterior. Por outro lado, os data lakes aceitam todos os tipos de formatos: estruturados, semiestruturados e não estruturados.
Nos data lakes podemos frequentemente encontrar imagens, vídeos ou textos que não encontramos nos data warehouses.
Processando informação
Os data warehouses seguem um processo denominado ETL (Extrair, Transformar e Carregar). A transformação e limpeza de dados são executadas antes do armazenamento no sistema de destino. Isso torna a economia mais lenta.
Em vez disso, os data lakes seguem ELT (Extract, Load and Transform), onde os dados são limpos e processados após serem salvos no sistema de destino.
Velocidade de ingestão
A velocidade de ingestão é maior em processos ELT, ou seja, em data lakes, pois não se perde tempo no processamento da informação antes do armazenamento.
Nos data warehouses há uma transformação da informação antes de salvá-la para garantir sua confiabilidade e que esteja de acordo com o esquema com o qual o data warehouse foi desenhado.
Proteção de dados
Os data warehouses possuem um melhor sistema de proteção de dados, pois já atuam no mercado há mais tempo.
Adaptação às mudanças
Os data lakes se adaptam mais facilmente às mudanças, pois um data warehouse, por ter uma estrutura pré-definida, dificulta o processo de adaptação às necessidades do cliente. Os data lakes, por não possuírem uma estrutura pré-definida, permitem maior versatilidade e agilidade.
Confiabilidade da informação
Os Data Warehouses permitem-nos obter informação mais detalhada e fiável, uma vez que os dados foram filtrados e limpos antes de serem guardados.
Por outro lado, em um data lake, os dados são brutos. Se alguém acessar o data lake com pouca experiência, poderá receber informações de baixa qualidade e não confiáveis.
Plataformas que usam Data Lakes
Existem algumas plataformas que permitem utilizar este tipo de arquitetura para armazenar todos os tipos de dados. Os mais famosos são AWS (Amazon Web Server), Azure, Google Cloud e Cloudera.
Todos eles possuem muita experiência com implementação de tecnologias de Big Data e Machine Learning, o que o ajudará em todos os momentos na implementação de data lakes.
Aprenda como usar os serviços em nuvem do Data Lakes
Existem cursos em plataformas de aprendizagem como a Udemy para aprender como gerenciar data lakes e data warehouses e se tornar um engenheiro de big data:
- Lago de dados na AWS
- Azure Data Factory para engenheiros de dados
- Armazenamento do Lago de Dados Azure Gen2