Qu'est-ce qu'un arbre de décision


Les arbres de décision sont un algorithme mathématique statistique utilisé dans le monde de la science des données et de l'apprentissage automatique pour faire des prédictions. Il s’agit d’une méthode d’apprentissage autonome supervisé qui peut être utilisée aussi bien pour des problèmes de classification que de régression.
Si vous souhaitez en savoir plus sur ces méthodes, restez et découvrez comment elles fonctionnent et quelles sont leurs principales utilisations.
Introduction aux arbres de décision
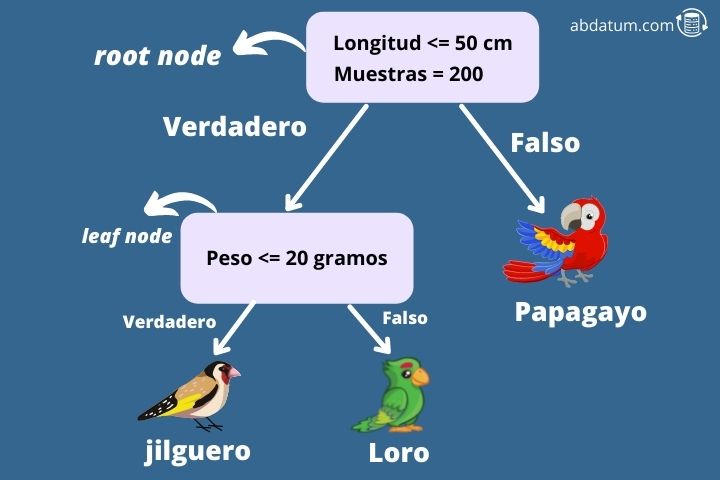
Pour mieux comprendre cet algorithme, donnons un exemple. Imaginez que nous voulions savoir, compte tenu de certaines caractéristiques, si un oiseau est un chardonneret, un inséparable ou un perroquet (problème typique de multiclassification à 3 classes). Pour ce faire, nous commençons à construire un arbre de décision à partir du nœud zéro.
Le premier nœud est appelé nœud racine et dans ce cas, il demande si les ailes de l'oiseau mesurent moins de 50 cm de long. Si tel est le cas, l’algorithme se déplace vers son nœud enfant droit. Ce type de nœud est appelé nœud feuille.
Le nœud suivant demande si le poids de l'oiseau est inférieur à 20 grammes. Dans le cas contraire, l’algorithme précise que l’espèce d’oiseau est un perroquet. Alternativement, s’il pèse moins de 20 grammes, c’est un chardonneret.
De cette façon, nous pouvons déterminer à quelle classe appartient une certaine entrée de notre ensemble de données. Mais comment construit-on un arbre de décision ?
La mission de l'algorithme d'arbre de décision est de créer des sous-ensembles de l'ensemble de données d'entraînement qui sont séparés par certaines des caractéristiques que nous avons données comme informations d'entrée, dans ce cas, par exemple, la longueur des ailes ou le poids de l'oiseau. .
Une métrique est utilisée dans chaque nœud, appelée impureté gini pour déterminer laquelle des caractéristiques nous donne le plus grand degré de séparation. La fonctionnalité qui nous permet de séparer l'ensemble de données de la manière la plus optimale est celle qui sera utilisée dans ce nœud comme critère de séparation.
Avantages de l'algorithme d'arbre de décision
Il est important de comprendre quels avantages et inconvénients nous apporte l’utilisation de ces types d’algorithmes d’apprentissage autonome supervisé. Vous trouverez ci-dessous les points forts de l’utilisation de ce type de modèle ainsi que ses limites.
- Méthodes d'apprentissage automatique non linéaires qui donnent un grande flexibilité du modèle.
- Les besoins en données peu de préparation puisque cet algorithme n'a pas besoin de mettre à l'échelle les caractéristiques pour qu'elles soient à des valeurs proches.
- Ils peuvent combinés pour construire des modèles plus robustes. Ceux-ci sont appelés assembleurs ou méthodes d’ensemble.
- Nous pouvons construire à la fois un modèle de classification comme modèle de régression.
- Facilement compréhensible puisque vous pouvez représenter graphiquement l'arbre de décision de chaque modèle et le comprendre visuellement, par exemple, à l'aide de la bibliothèque Python Graphviz.
Limites des arbres de décision
- Les arbres de décision ont des limites de décision (limites de décision) orthogonal donc les résultats sont sensible à la rotation des données de l’ensemble de données. Cela peut poser des problèmes dans la généralisation du modèle.
- C'est une méthode très sensible aux petites variations dans l’ensemble de données d’entraînement.
-
Des modèles très complexes peuvent être construits et donner naissance à ce que l'on appelle
surapprentissage ou surapprentissage
où les données correspondent très bien aux données d'entraînement mais
Le modèle ne généralise pas bien. Des techniques telles que la taille peuvent être utilisées pour réduire cet effet. - Trouver l'arbre de décision le plus optimal est un problème mathématique appelé NP-complet. Ces types de problèmes empêchent de trouver la solution la plus optimale, c'est pourquoi des méthodes heuristiques sont utilisées dans le but de se rapprocher le plus possible de la réponse la plus optimale pour un problème donné.
Apprentissage conjoint ou apprentissage d'ensemble
Maintenant que nous comprenons à peu près comment fonctionnent les arbres de décision, nous allons donner une introduction à des algorithmes beaucoup plus puissants qui utilisent les arbres de décision.
Il apprentissage d'ensemble former différents arbres de décision pour différents sous-ensembles de données du ensemble de données de formation. Pour prédire un résultat, on obtient la réponse pour chacun des arbres et enfin on choisit le résultat qui a eu le plus de votes.
En règle générale, les méthodes d'apprentissage conjoint sont plus utilisées que les arbres de décision séparés, car elles améliorent la précision des prédictions et diminuent les risques. surapprentissage ou un surapprentissage.
Certains méthodes d'assemblage Les plus populaires qui peuvent utiliser des arbres de décision comme prédicteurs sont :
- Ensachage : Cette méthode consiste à entraîner différents sous-ensembles de l'ensemble de données d'entraînement avec différents prédicteurs. Si le même prédicteur peut être utilisé plusieurs fois, la méthodologie est appelée Bagging. Au contraire, si l’échantillonnage se produit sans remplacement, on parle alors de collage. Un exemple d'ensachage utilisé avec les prédicteurs d'arbre de décision est la forêt aléatoire.
- Booster : Les méthodes de boosting visent à concaténer différents prédicteurs où chacun doit améliorer le résultat du précédent. Les algorithmes de boosting les plus populaires sont AdaBoost ou Gradient Boosting. XGBoost est une bibliothèque populaire qui utilise l'augmentation de gradient à l'aide d'arbres de décision.