Qu'est-ce que le surapprentissage


Le surajustement, ou mieux connu sous sa traduction anglaise, le surajustement, est une propriété du modèle statistique qui nous indique qu'il ne pourra pas généraliser de manière adéquate à d'autres données avec lesquelles il n'a pas été entraîné.
Le surajustement se produit lorsque, lors de la construction d'un modèle d'apprentissage automatique, la méthode utilisée donne trop de flexibilité aux paramètres et finit par générer un modèle qui correspond parfaitement aux données qui ont été entraînées mais qui n'est pas capable de remplir la fonction de base d'un modèle. : être capable de généraliser à de nouvelles informations.
Le surapprentissage est l’un des principaux problèmes de l’apprentissage autonome et de l’intelligence artificielle en général. Si nous ne parvenons pas à détecter ce problème, notre modèle sera de très mauvaise qualité même s’il présente de bons résultats de prédiction dans l’ensemble d’apprentissage.
Il existe différentes manières de détecter et d'éviter le surajustement dans le modèle de prédiction. La plupart de ces techniques consistent à réduire la complexité du modèle afin qu'il s'adapte moins à l'ensemble d'apprentissage et puisse se généraliser à de nouvelles observations.
Comment détecter le surajustement ou le surajustement
Comme nous l’avons vu, le diagnostic de notre modèle devrait être une étape obligatoire avant de le mettre en production. Dans le cas contraire, les prédictions faites pourraient s’avérer inexactes et notre projet pourrait ne pas fonctionner comme il le devrait. Ci-dessous, nous montrons quelques contrôles que nous pouvons effectuer pour détecter le niveau de surajustement ou de sous-apprentissage dont souffre notre modèle statistique.
Compromis biais-variance
Il est important de connaître le concept d’équilibre entre biais et variance dans le monde de l’apprentissage automatique. En apprentissage automatique, notre objectif est de pouvoir construire une fonction f' aussi proche que possible de la fonction f originale qui modélise le comportement de nos données.
Lorsque nous formons un modèle, nous construisons essentiellement la fonction f' à partir des données que nous utilisons en entrée.
La variance représente dans quelle mesure la fonction f' varie lors du changement de l'ensemble d'apprentissage. Si cela change beaucoup, on dit que le modèle statistique a une variance élevée, donc il souffre sûrement de surajustement puisqu'il est capable de modéliser parfaitement les données d'entraînement, mais en généralisant à des données qu'il n'a jamais vues, il échoue.
Nous pouvons définir le biais comme étant le contraire. Si, lors de l'utilisation de différents ensembles d'apprentissage, la fonction f' reste pratiquement la même, alors le modèle présente une faible variance et un biais élevé. Cela indique que nous avons un sous-ajustement, donc le modèle est trop simple et ne s'adapte pas bien aux données de formation ou de validation.
Ce que nous devrions essayer lors de la construction de nos modèles, c'est un équilibre entre variance et biais.
Dans la section suivante, nous vous apprendrons une technique avec laquelle vous pourrez détecter visuellement ces problèmes.
Courbes d'apprentissage
Les courbes d'apprentissage ou courbes d'apprentissage en anglais sont l'une des meilleures méthodes pour diagnostiquer notre modèle en cas de problèmes de surajustement (variance élevée) ou de sous-ajustement (biais élevé).
Dans un graphique de courbe d'apprentissage typique, nous avons une métrique d'erreur sur l'axe des ordonnées, par exemple, le MSE (Erreur quadratique moyenne) et l'axe des coordonnées a différentes tailles de l'ensemble d'entraînement.
Les fonctions d'apprentissage nous diront comment l'erreur du modèle varie en fonction de la taille de l'ensemble de données d'apprentissage.
En cas de surajustement ou de variance élevée, le graphique montrera l'écart important entre les données de validation et les données d'entraînement. En effet, le modèle s'adapte très bien aux données d'entraînement, de sorte que l'erreur dans l'ensemble d'entraînement sera très faible. Cependant, il n’est pas possible de généraliser. Pour cette raison, l’erreur dans l’ensemble de validation sera beaucoup plus importante. Dans le graphique suivant, nous pouvons voir les courbes d'apprentissage typiques d'un modèle surentraîné.
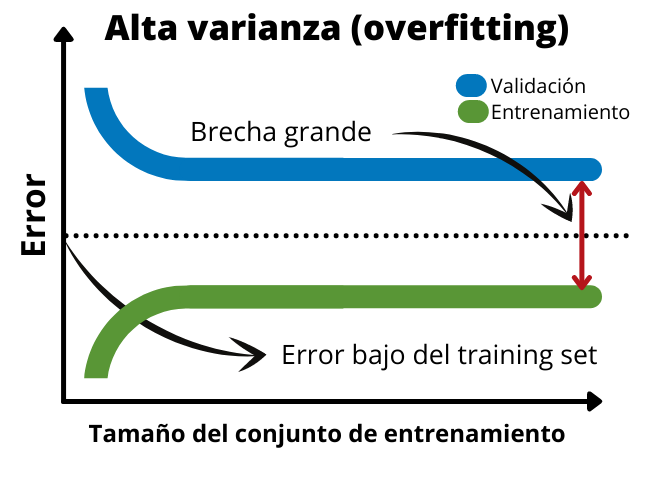
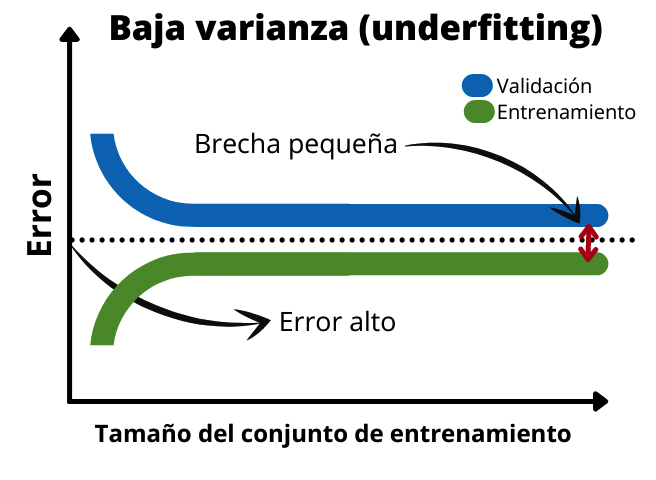
Lorsque nous avons un biais élevé ou un sous-ajustement, l’écart entre les deux fonctions est très faible. De plus, l’erreur de l’ensemble de validation et de l’ensemble de formation est élevée. Cela indique qu'il s'agit d'un modèle très simple qui ne s'adapte pas bien aux données. Dans ce cas, il serait nécessaire d'ajouter plus de données de formation ou d'augmenter le temps de formation du modèle.
Comment résoudre le surapprentissage
Le surajustement est un problème très courant et les data scientists doivent constamment y faire face. Nous présenterons ensuite certaines des techniques les plus utilisées par les data scientists du monde entier pour éliminer le surajustement et améliorer la généralisation des modèles.
1. Simplification du modèle
La première étape consiste à réduire la complexité du modèle. La manière de procéder dépendra de la méthode d’apprentissage automatique utilisée.
Dans les réseaux de neurones, nous pouvons réduire le nombre de couches ou de neurones. On peut également utiliser des techniques de régularisation comme le décrochage ou l'arrêt anticipé.
Dans le cas où nous utilisons des arbres de décision, nous pouvons utiliser une technique appelée élagage.
Dans d’autres cas, comme les Machines à Vecteurs de Support (SVM) ou les techniques de régression, la régularisation des modèles se fait grâce à leurs hyperparamètres, qui ajoutent des restrictions, limitant la flexibilité.
2. Techniques d'augmentation des données
Ces techniques consistent à générer de nouvelles données à partir de données existantes. Par exemple, dans un ensemble d'images, certaines transformations que nous pouvons appliquer et qui généreraient de nouveaux échantillons sont des traductions, des rotations, des mises à l'échelle, des filtres ou des changements d'éclairage.
3. Éliminez le bruit de l'ensemble d'entraînement
Dans certains cas, le surapprentissage peut être dû à un mauvais nettoyage des données. Lorsque nous recevons les données brutes, nous devons effectuer ce que l'on appelle le nettoyage des données pour éliminer les valeurs aberrantes, standardiser les données et supprimer les informations qui pourraient ajouter du bruit à notre modélisation.
En effectuant des processus de nettoyage des données, nous pouvons réduire la variance, améliorant ainsi les résultats finaux.
4. Obtenez plus d'observations
Obtenir plus de données pourrait aider à résoudre le problème. Cependant, il est également possible que ce ne soit pas le cas et nous devrons utiliser l’une des autres méthodologies de cette section.
5. Transférer les techniques d’apprentissage
Dans certains cas, le problème de surapprentissage peut être dû au peu de données dont nous disposons. Il est également possible que davantage de données ne puissent pas être acquises en augmentant l'ensemble de données.
À ce stade, nous pouvons recourir à d’autres types de solutions telles que l’apprentissage par transfert, ou mieux connu sous le nom d’apprentissage par transfert. Cette solution consiste à adopter un modèle déjà entraîné et fonctionnel qui remplit une fonction similaire et à le recycler avec notre petit ensemble de données.
Implémentation en Python
Dans cet article sur le blog abdatum, nous avons vu ce qu'est le surapprentissage ou le surapprentissage, comment le détecter et comment le résoudre. Nous avons également expliqué que les courbes d’apprentissage sont l’une des meilleures méthodes pour diagnostiquer le modèle d’apprentissage automatique. Comment créer des courbes d’apprentissage ?
Nous pouvons le faire manuellement. Cependant, le package Python sklearn inclut le courbe d'apprentissage à l’intérieur de model_selection. Dans cette fonction, nous devons transmettre l'estimateur que nous utiliserons pour construire le modèle et l'ensemble de données d'entraînement.
À partir des informations renvoyées, nous pouvons tracer les courbes à l'aide de la bibliothèque matplotlib.