Qué es el overfitting


El sobreajuste o más conocido por su traducción en inglés, overfitting, es una propiedad del modelo estadístico que nos indica que no será capaz de generalizar adecuadamente a otros datos con los que no ha sido entrenado.
El overfitting sucede cuando al construir un modelo de machine learning, el método empleado da demasiada flexibilidad a los parámetros y se acaba generando un modelo que encaja perfectamente con los datos que ha sido entrenados pero que no es capaz de realizar la función básica de un modelo estadístico: ser capaz de generalizar a nueva información.
El sobreajuste es uno de los principales problemas del aprendizaje autónomo, y en general, de la inteligencia artificial. Si no somos capaces de detectar dicho problema nuestro modelo será de muy mala calidad aun teniendo buenos resultados de predicción en el training set o conjunto de entrenamiento.
Existen diferentes formas de detectar y evitar tener un sobreajuste en el modelo de predicción. La mayoría de estas técnicas consisten en reducir la complejidad del modelo para que se adapte menos al conjunto de entrenamiento y sea capaz de generalizar a nuevas observaciones.

Cómo ser un Data Scientist
Data Scientist es una de las profesiones con mejores condiciones laborales del presente y del futuro. Aprende qué necesitas para ser un científico de datos.
Ver artículoComo detectar el sobreajuste o overfitting
Como hemos visto, diagnosticar nuestro modelo debe ser un paso obligatorio antes de ponerlo en producción. De no ser así, las predicciones hechas pueden ser poco precisas y que nuestro proyecto no funcione como debe. Seguidamente mostramos algunas comprobaciones que podemos hacer para detectar el nivel de overfitting o underfitting que sufre nuestro modelo estadístico.
Compensación del sesgo y la varianza (bias-variance trade-off)
Es importante saber el concepto de equilibro entre el sesgo y la varianza dentro del mundo del machine learning. En el machine learning, nuestro objetivo es ser capaz de construir una función f’ que se aproxime al máximo a la función original f que modela el comportamiento de nuestros datos.
Cuando entrenamos un modelo, básicamente lo que estamos haciendo es construir la función f’ a partir de los datos que utilizamos como input.
La varianza representa cuanto varia la función f’ al cambiar el training set. Si está cambia mucho decimos que el modelo estadístico tiene una alta varianza, por lo que seguramente sufra de overfitting ya que es capaz de modelar perfectamente los datos de entrenamiento, pero al generalizar a datos que nunca ha visto entonces falla.
El bias podemos definirlo como el contrario. Si al utilizar distintos conjuntos de entrenamiento, la función f’ se mantiene prácticamente igual entonces el modelo tiene una baja varianza y un alto bias. Esto nos indica que tenemos underfitting, por lo que, el modelo es demasiado sencillo y no se ajusta bien ni a los datos de entrenamiento ni a los de validación.
Otros posts que te gustarán
Lo que debemos intentar al construir nuestros modelos es un equilibrio entre la varianza y el bias (o sesgo).
En la siguiente sección te enseñaremos una técnica con lo que puedes detectar visualmente estos problemas.
Las curvas de aprendizaje
Las curvas de aprendizaje o learning curves en inglés es uno de los mejores métodos para diagnosticar nuestro modelo de posibles problemas de overfitting (alta varianza) o underfitting (alto bias).
En un gráfico típico de curvas de aprendizaje tenemos en el eje de ordenadas una métrica de error, por ejemplo, el MSE (Mean-Squared Error) y el eje de coordenadas distintos tamaños del training set.
Las funciones de aprendizaje nos indicarán como varia el error del modelo respecto el tamaño del conjunto de datos de aprendizaje.
En el caso de sobreajuste o alta varianza el gráfico mostrará como existe una brecha grande entre los datos de validación y los de entreno. Esto se debe a que el modelo se ajusta muy bien a los datos de entrenamiento por lo que el error en el training set será muy bajo. Sin embargo, no es capaz de generalizar. Por esta razón, el error en el validation set será mucho mayor. En el siguiente gráfico podemos ver las típicas curvas de aprendizaje de un modelo sobreentrenado.
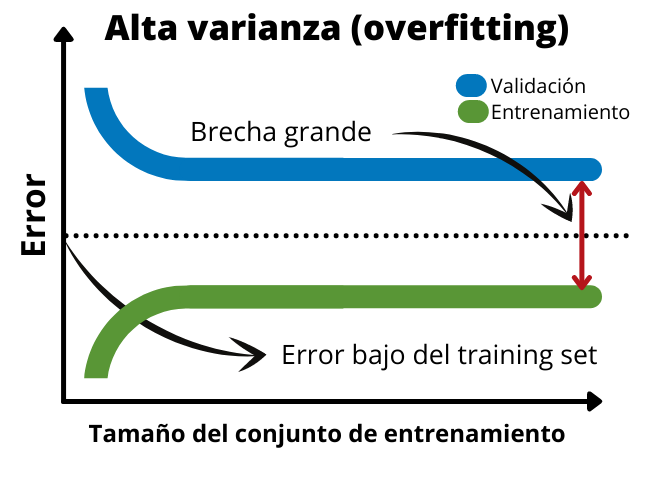
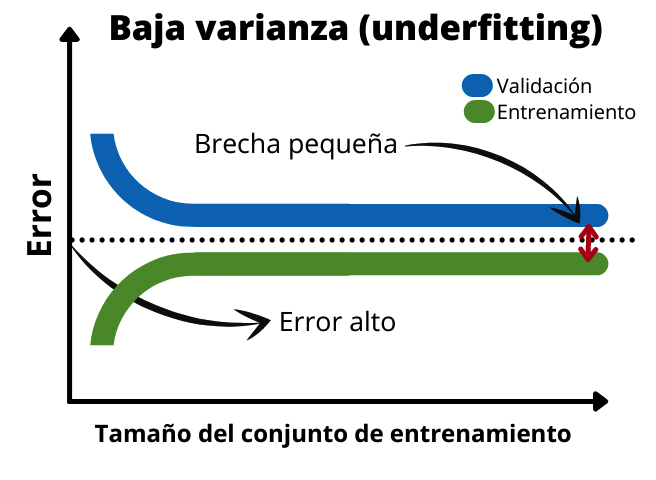
Cuando tenemos un bias alto o underfitting la brecha entre las dos funciones es muy pequeña. Además, el error del set de validación y el de entrenamiento es alto. Esto indica que es un modelo muy sencillo que no se ajusta bien a los datos. En este caso seria necesario añadir más datos de entrenamiento o aumentar el tiempo de entrenamiento del modelo.
Cómo solucionar el overfitting
El sobreajuste es un problema muy común y los data scientists deben estar constantemente lidiando con él. Seguidamente mostraremos algunas de las técnicas más usadas por científicos de datos de todo el mundo para eliminar el sobreajuste y mejorar la generalización del modelo.
1. Simplificación del modelo
El primer paso es reducir la complejidad del modelo. La manera de llevar a cabo esto va a depender del método de machine learning usado.
En redes neuronales podemos disminuir el número de capas o neuronas. También podemos utilizar técnicas de regularización como el dropout o el early stopping.
En el caso que estemos usando árboles de decisión podemos emplear una técnica conocida como pruning.
En otros casos como Support Vector Machines (SVM) o técnicas de regresión, la regularización de los modelos se consigue a través de sus hiperparámetros, los cuales añaden restricciones limitando la flexibilidad.
2. Técnicas de data augmentation
Estas técnicas consisten en generar nuevos datos a partir de los ya existentes. Por ejemplo, en un conjunto de imágenes, algunas transformaciones que podemos aplicar las cuales generarían nuevas muestras son translaciones, rotaciones, escalados, filtros o cambios en la iluminación.
3. Eliminar ruido del training set
En algunos casos, el overfitting puede ser debido a una mala limpieza de los datos. Cuando recibimos los datos en crudo debemos realizar lo que se conoce como data cleaning para eliminar outliers, estandarizar los datos y suprimir información que pueda añadir ruido a nuestro modelaje.
Realizando procesos de limpieza de datos podemos reducir la varianza mejorando los resultados finales.
4. Conseguir más observaciones
Conseguir más datos podría ayudar a solucionar el problema. No obstante, también es posible que no sea así y tengamos que usar alguna de las otras metodologías de esta sección.
5. Técnicas de transfer learning
En algunos casos, el problema de sobreajuste puede ser debido a los pocos datos que tenemos. También es posible que no se puedan adquirir más datos aumentando el dataset.
En este punto podemos recurrir a otro tipo de soluciones como son la transferencia de aprendizaje, o más conocido como transfer learning. Esta solución consiste en adoptar un modelo ya entrenado y funcional que realiza una función parecida y reentrenarlo con nuestro pequeño conjunto de datos.
Implementación en Python
En este artículo del blog de abdatum hemos visto que es el overffiting o sobreajuste, como detectarlo y como solucionarlo. También hemos explicado que las curvas de aprendizaje son uno de los mejores métodos para hacer el diagnostico del modelo de machine learning. ¿Cómo creamos las learning curves?
Podemos hacerlo manualmente. No obstante, el paquete de Python sklearn incluye la función de learning_curve dentro de model_selection. En esta función le tenemos que pasar el estimador que usaremos para construir el modelo y el dataset de entrenamiento.
A partir de la información que nos devuelve podemos graficar las curvas usando la librería de matplotlib.