Redes neurais artificiais


O mundo da inteligência artificial evoluiu muito durante a última década. Esse avanço se deve principalmente à evolução de um tipo de algoritmo denominado rede neural.
O que são redes neurais?
A teoria das redes neurais existe há muitos anos, desde por volta da década de 1960. No entanto, não tínhamos as ferramentas matemáticas necessárias para poder aplicá-las na prática em nosso mundo até alguns anos atrás.
O objetivo deste tipo de redes, conhecidas em inglês como redes neurais , está tentando simular o funcionamento do nosso cérebro para criar um modelo que seja capaz de atuar como uma inteligência. Portanto, podemos dizer que:
Uma rede neural artificial é um modelo matemático composto por diversas operações que visa emular o comportamento dos nossos neurônios para aprender com a experiência, ou seja, com os dados iniciais.
Em suma, o que as redes neurais ou a inteligência artificial fazem é imitar a aprendizagem humana. Tudo o que sabemos é graças à experiência dos nossos anos de vida. Quando nascemos, nosso cérebro fica em branco e, à medida que vivenciamos, ele se enche de conhecimento e sabedoria.
As redes neurais funcionam de maneira semelhante. Quando inicializados, eles ficam em branco e não contêm informações valiosas. No entanto, à medida que alimentamos a rede de dados, ela aprende e é capaz de tomar decisões com base na experiência, ou seja, a partir dos dados que lhe fornecemos.
O perceptron: a unidade básica da rede
Podemos considerar o perceptron como a unidade básica de uma rede neural . Matematicamente é um classificador binário linear que pode aprender a classificar duas classes diferentes.
Por exemplo, se tivermos um grupo de imagens de cães e gatos misturadas, um perceptron seria capaz de diferenciar a imagem de um gato da de um cachorro.
No entanto, é um modelo muito simples que atualmente só é usado para explicar como funcionam as redes neurais, que são simplesmente muitos perceptrons interligados.
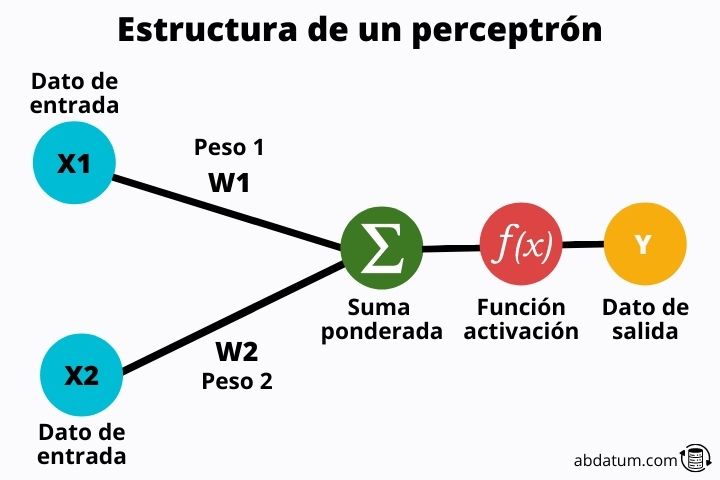
Vamos ver quais partes um perceptron possui:
Valores de entrada
Esses valores são os informações que entram no perceptron . Estas são características de cada uma das classes a serem classificadas.
Por exemplo, se falamos de animais, algumas das características podem ser a cor do cabelo, a cor dos olhos, o número de patas, o tipo de cabelo, etc.
Esses valores serão transformados através de um conjunto de operações matemáticas.
Pesos dos ingressos
Os pesos são valores aleatórios que são multiplicados pelos valores de entrada . Esses pesos são basicamente o que permite que uma rede neural aprenda. A princípio são valores aleatórios, mas aos poucos, à medida que a rede neural é inserida, eles são otimizados para dar os melhores resultados possíveis.
Funções de ativação
Uma vez multiplicadas as características pelos pesos, elas são somadas e o valor resultante é passado através do que é conhecido como função de ativação.
Posteriormente entraremos em detalhes sobre o que é esta função, mas em resumo, sua missão é controlar a aprendizagem do perceptron ou mais geralmente da rede neural.
Graças a essas funções, as redes neurais são altamente flexíveis e podem aprender todos os tipos de tarefas.
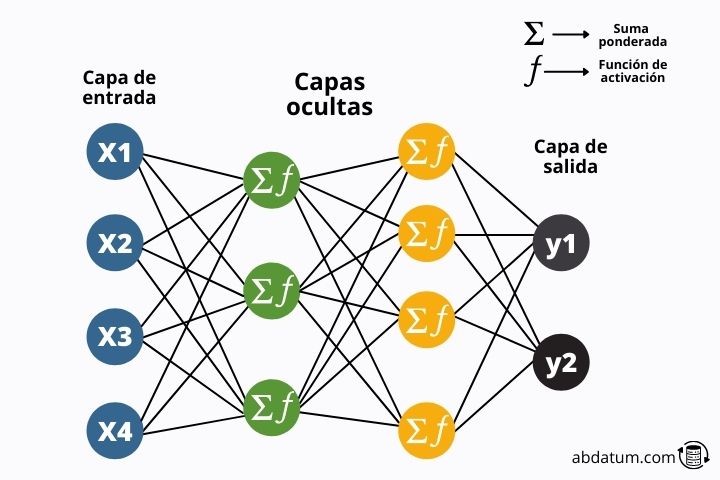
Camadas de rede neural
Vimos, em termos gerais, que se trata de um perceptron. Agora podemos começar com redes neurais artificiais.
As redes neurais Eles são simplesmente uma combinação de muitos perceptrons. De agora em diante, chamaremos esses perceptrons de neurônios.
Portanto, uma rede neural artificial é simplesmente um conjunto de neurônios unidos formando diferentes camadas .
No diagrama a seguir podemos ver a estrutura típica desses modelos matemáticos.
A informação flui pela rede até chegar ao final da rede onde os resultados são comparados com a informação real. Vejamos isso com mais detalhes:
Treinamento de redes neurais
O que as redes neurais fazem é transformar valores de entrada em valores de saída graças às múltiplas operações matemáticas que contêm, como adição ou multiplicação.
Os valores de saída devem ser comparados com os valores reais. Por exemplo, se a rede neural nos diz que a imagem é um cachorro, temos que dizer se está correta ou errada.
Isto é conseguido graças ao função de perda ou custo (em inglês função de perda ). Esta função matemática informa à rede quanto ou quão pouco ela cometeu um erro.
Desta forma, o algoritmo pode otimizar os pesos para minimizar a função de erro. Essa minimização permitirá que os resultados sejam muito melhores na próxima vez.
Isso é feito iterativamente durante diferentes ciclos. Esses ciclos são chamados de épocas e o conjunto de operações realizadas para minimizar a função de custo é chamado de treinamento.
Portanto, treinar uma rede neural consiste no seguinte:
- Os pesos são inicializados aleatoriamente em toda a rede.
- Os dados de entrada são operados na rede multiplicando-se pelos pesos aleatórios e transformados pelas funções de ativação.
- Os dados transformados chegam ao final da rede e são comparados com os resultados reais.
- É criada uma função de custo que determina o grau de erro na rede.
- Os pesos são ajustados para minimizar o erro.
- Os dados entram novamente na rede com os pesos otimizados e este ciclo é repetido por várias épocas até que o erro seja mínimo.
Retropropagação
O algoritmo de retropropagação foi o herói da inteligência artificial. Antes de sua descoberta não havia como treinar redes neurais artificiais.
Como mencionamos antes, a teoria é conhecida há décadas. Porém, devido à falta de recursos computacionais e deste algoritmo, as redes não puderam ser treinadas.
Este algoritmo permite-nos minimizar todos os pesos das redes, que podem ser milhões e milhões, num tempo razoável, aplicando diferentes métodos matemáticos de análise funcional.
A regra da cadeia de diferenciação matemática de funções é usada para encontrar os valores que minimizam o erro.
Minimizadores de função de custo
Existem vários algoritmos que permitem otimizar funções matemáticas. O mais conhecido no mundo da inteligência artificial é a descida gradiente.
Este método consiste em encontrar o vetor que define a descida mais acentuada para atingir mais cedo um mínimo local da função.
Se a forma da função perda for quadrática, esse mínimo local é o mínimo global, o que evita muitos dos problemas que veremos a seguir.
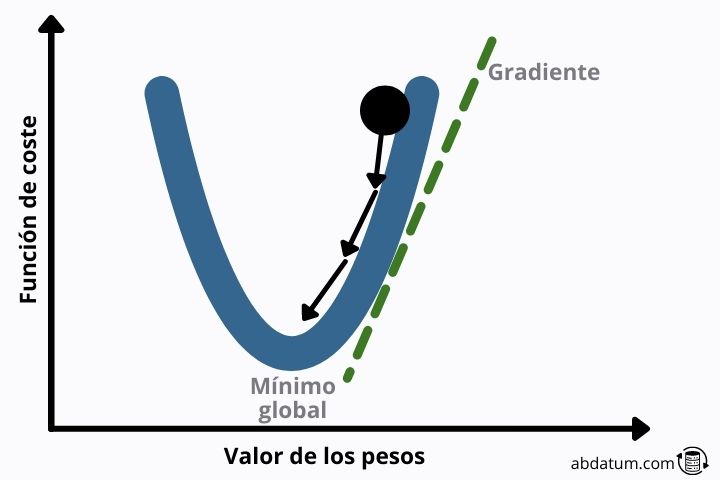
Problema de desvanecimento do gradiente
Em redes com muitas camadas, o gradiente deve se propagar através de todos os pesos da rede neural. Aos poucos esse gradiente vai ficando cada vez menor.
Em valores muito próximos de zero, o gradiente não serve mais para otimizar a rede neural e, portanto, o treinamento para.
Uma das melhores soluções é usar o que é conhecido como pular conexões . Esta arquitetura permite criar conexões entre neurônios distantes que não vêm da camada anterior.
Dessa forma, a informação pode fluir ignorando alguns neurônios, evitando o problema do desvanecimento do gradiente.
Problema de gradiente explosivo ou gradiente explosivo
O problema do gradiente explosivo é o oposto do que vimos na seção anterior. Alguns tipos de funções de ativação geram grandes valores numéricos.
Isto pode levar a valores de gradiente muito elevados, desestabilizando a rede neural e gerando previsões muito imprecisas.
Um dos métodos para evitar o gradiente explosivo é conhecido como recorte gradiente e consiste em redimensionar o gradiente para que a norma do vetor fique dentro de uma determinada faixa.
Tipos de redes neurais
Existem muitas arquiteturas diferentes de redes neurais. Dependendo de como os conectamos e do tipo de operações realizadas no seu interior, corresponderão a um tipo ou outro.
Redes Neurais Feedforward
Redes neurais pré-alimentadas ou em inglês redes neurais feed forward Constituem um tipo de arquitetura onde a informação apenas flui para frente, não há loops ou conexões entre neurônios da mesma camada.
Eles são formados pela união de diferentes perceptrons responsáveis pela transformação dos dados de entrada.
Este tipo de redes neurais são as mais simples e foram as primeiras a serem implementadas para realizar tarefas de inteligência artificial.
Redes neurais convolucionais
As redes convolucionais, também conhecidas como redes neurais convolucionais (CNN), possuem uma arquitetura ideal para trabalhar com imagens.
Os pesos desse tipo de rede formam filtros capazes de detectar diferentes características de uma foto, como sombras, bordas ou o formato do olho humano.
Um grande número de filtros é aplicado à medida que as informações fluem de camada para camada. Esses filtros são responsáveis por classificar a imagem ao final do processo.
Em 2012, um modelo denominado ImageNet treinado com este tipo de redes neurais foi capaz de classificar até 1.000 objetos diferentes em um conjunto de um milhão de imagens.
Naquela época, viu-se o potencial das CNNs em realizar inteligência artificial com imagens de todos os tipos.
Redes neurais recorrentes
Redes neurais recorrentes são um tipo de rede que pode formar ciclos, ou seja, um neurônio pode estar conectado a si mesmo.
Graças ao uso de recorrência, redes recorrentes como LSTM ( Memória de longo e curto prazo ) ou as GRUs ( Unidade recorrente fechada ) são capazes de memorizar e lembrar sequências que analisaram anteriormente.
Isso permite que essas redes artificiais sejam muito eficazes na análise de dados que possuem uma estrutura sequencial. Um exemplo são os textos.
Uma frase pode se referir a um evento anterior, que aconteceu há algumas linhas de texto. Graças à recorrência, essas redes são capazes de lembrar e relacionar sequências de texto distantes entre si.
Outro tipo de aplicação de rede recorrente é a análise de séries temporais. Muitas empresas usam essa arquitetura para fazer previsões de vendas de produtos com base em uma sequência de vendas do ano anterior.