O que é uma árvore de decisão


As árvores de decisão são um algoritmo matemático estatístico usado no mundo da ciência de dados e do aprendizado de máquina para fazer previsões. É um método de aprendizagem autônoma supervisionada que pode ser usado tanto para problemas de classificação quanto para problemas de regressão.
Se quiser saber mais sobre esses métodos, fique e descubra como funcionam e quais são suas principais utilizações.
Introdução às árvores de decisão
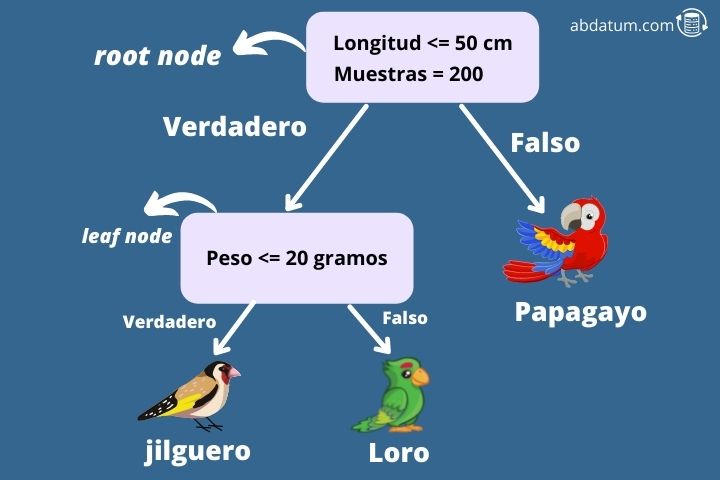
Para entender melhor esse algoritmo, vamos dar um exemplo. Imagine que queremos saber, dadas algumas características, se um pássaro é um pintassilgo, um periquito ou um papagaio (problema típico de multiclassificação de 3 classes). Para fazer isso, começamos a construir uma árvore de decisão a partir do nó zero.
O primeiro nó é conhecido como nó raiz e neste caso pergunta se as asas do pássaro têm menos de 50 cm de comprimento. Nesse caso, o algoritmo move-se para o nó filho direito. Este tipo de nó é chamado de nó folha.
O próximo nó pergunta se o peso da ave é inferior a 20 gramas. Caso contrário, o algoritmo especifica que a espécie de ave é um papagaio. Alternativamente, se pesar menos de 20 gramas é um pintassilgo.
Desta forma, podemos determinar a qual classe pertence uma determinada entrada em nosso conjunto de dados. Mas como é construída uma árvore de decisão?
A missão do algoritmo de árvore de decisão é criar subconjuntos do conjunto de dados de treinamento que são separados por algumas das características que demos como informação de entrada, neste caso, por exemplo, o comprimento das asas ou o peso do pássaro .
Uma métrica é usada em cada nó, que é chamada impureza de gini para determinar qual das características nos dá um maior grau de separação. O recurso que nos permite separar o conjunto de dados de maneira ideal é aquele que será usado naquele nó como critério de separação.
Vantagens do algoritmo de árvore de decisão
É importante compreender quais as vantagens e desvantagens que a utilização deste tipo de algoritmos de aprendizagem autónoma supervisionada nos traz. Abaixo você encontrará os destaques da utilização desse tipo de modelo bem como suas limitações.
- Métodos não lineares de aprendizado de máquina que fornecem uma grande flexibilidade ao modelo.
- Os dados precisam pouca preparação já que este algoritmo não precisa dimensionar os recursos para que fiquem em valores próximos.
- Eles podem combinados para construir modelos mais robustos. Estes são conhecidos como montadores ou métodos de conjunto.
- Podemos construir tanto um modelo de classificação como de regressão.
- Facilmente compreensível, pois você pode gráfico da árvore de decisão de cada modelo e entendê-lo visualmente, por exemplo, usando a biblioteca Python Graphviz.
Limitações das árvores de decisão
- As árvores de decisão têm limites de decisão (limites de decisão) ortogonal então os resultados são sensível à rotação dos dados do conjunto de dados. Isso pode levar a problemas na generalização do modelo.
- É um método muito sensível a pequenas variações no conjunto de dados de treinamento.
-
Modelos muito complexos podem ser construídos e dar origem ao que é conhecido como
overfitting ou overfitting
onde os dados se ajustam muito bem aos dados de treinamento, mas
O modelo não generaliza bem. Técnicas como poda podem ser utilizadas para reduzir esse efeito. - Encontrar a árvore de decisão ideal é uma tarefa problema matemático denominado NP-completo. Esses tipos de problemas impedem que a solução ideal seja encontrada, portanto, métodos heurísticos são utilizados com o objetivo de chegar o mais próximo possível da resposta ideal para um determinado problema.
Aprendizagem conjunta ou aprendizagem em conjunto
Agora que entendemos aproximadamente como funcionam as árvores de decisão, faremos uma introdução a algoritmos muito mais poderosos que fazem uso de árvores de decisão.
Ele aprendizagem em conjunto treinar diferentes árvores de decisão para diferentes subconjuntos de dados do conjunto de dados de treinamento. Para prever um resultado, obtém-se a resposta para cada uma das árvores e por fim é escolhido o resultado que teve mais votos.
Normalmente, os métodos de aprendizagem conjunta são mais utilizados do que as árvores de decisão separadas, uma vez que melhoram a precisão das previsões e diminuem o sobreajuste ou sobreajuste.
Alguns dos métodos de montagem Os mais populares que podem usar árvores de decisão como preditores são:
- Ensacamento: Este método consiste em treinar diferentes subconjuntos do conjunto de dados de treinamento com diferentes preditores. Se o mesmo preditor puder ser usado várias vezes, a metodologia será chamada de Bagging. Pelo contrário, se a amostragem ocorre sem reposição, é chamada de colagem. Um exemplo de empacotamento usado com preditores de árvores de decisão é a floresta aleatória.
- Impulsionando: Os métodos de boosting visam concatenar diferentes preditores onde cada um deve melhorar o resultado do anterior. Os algoritmos de boost mais populares são AdaBoost ou Gradient Boosting. XGBoost é uma biblioteca popular que usa aumento de gradiente usando árvores de decisão.